Méthodologie de l’étude : l’influence du social commerce
Partie 2 : Méthodologie
I. Objectifs de l’étude et collecte des données
Dans cette partie nous présentons la méthodologie utilisée au cours de l’étude. Le questionnaire a été réalisé via Google Form. Nous avons tout d’abord réalisé un questionnaire.
Puis nous l’avons soumis à nos connaissances sur Facebook par l’intermédiaire de Messenger, ainsi qu’à notre réseau professionnel par l’intermédiaire de Linkedin.
A. Objectifs de la recherche et méthodologie
Nous souhaitons déterminer les évolutions des comportements d’achat des consommateurs sur un réseau social. Nous avons donc décidé de réaliser une étude quantitative, qui est utilisée pour répondre à ce type de problématique.
Plus précisément, l’objectif de cette étude est d’analyser l’influence des fonctionnalités commerciales intégrées au sein d’un réseau social sur la fidélité des internautes.
Nous avons choisi le réseau social Facebook, car on y retrouve le plus d’utilisateurs actifs par mois, soit 2,234 milliards en 2019 d’après le Blog Du Modérateur, le média des professionnels du digital.
De plus, la période de confinement actuelle du fait du Covid-19 favorise le nombre d’internautes connectés sur le réseau.
Les internautes peuvent visualiser différents produits sur des pages Facebook commerciales. Nous souhaitons donc déterminer s’ils sont fidèles à ce réseau social.
Nous nous sommes basés sur la page commerciale de CDiscount sur Facebook, dont le siège social se trouve à bordeaux, pour mener notre étude car une grande partie de notre échantillon se situe dans cette ville.
De plus, il s’agit d’une entreprise française ce qui permettra aux répondants de s’identifier plus facilement à l’étude.
L’étude quantitative nous permettra de connaître les comportements, attentes et opinions du consommateur, grâce à un échantillon représentatif. Cet échantillon est composé de notre réseau personnel et professionnel.
B. Le questionnaire1,2
Pour constituer notre questionnaire nous nous sommes appuyés sur des échelles de mesures validées.
Ces échelles de mesures sont issues de trois articles différents dont principalement l’article “La relation entre la perception de la qualité et la fidélité :
Une application aux sites web commerciaux.” de Boyer A. et Nefzi A. (Boyer & Nefzi, 2008) deux chercheurs qui se sont basés à la fois sur l’échelle Netqual proposée par G. Bressolles en 2004 (Boyer & Nefzi, 2008) ainsi que sur les résultats des entretiens réalisés lors de l’élaboration de leur étude qualitative.
Les articles “Les composantes de la relation dans les e-services : comment créer la fidélité à l’égard d’un portail Internet ?” de Allagui A. et Temessek A ainsi que “Orientations de shopping et intention d’achat en ligne.” de ZAOUI I., ont aussi été utilisés pour trouver des échelles de mesures satisfaisantes (Allagui & Temessek, 2013; Zaoui, 2009).
La mesure de la qualité perçue a été réalisée grâce au développement d’une batterie d’items basée à la fois sur l’échelle Netqual proposée par G. Bressolles en 2004 (Boyer & Nefzi, 2008) ainsi que sur les résultats des entretiens réalisés lors de l’élaboration de leur étude qualitative.
Pour évaluer l’influence que peut exercer la facilité d’utilisation d’un réseau social sur la satisfaction de l’internaute, nous avons utilisé l’échelle de mesure correspondante utilisée par Boyer A. et Nefzi A. (issue de l’échelle de Netqual proposée par G. Bressolles en 2004 dans leurs travaux). Cette échelle comprend 5 items.
Cette échelle de mesure a été développée dans le but d’analyser l’influence de la facilité d’utilisation d’un site sur la satisfaction des internautes.
C’est pourquoi nous l’avons adaptée dans notre étude en remplaçant le mot “site” par “réseau”.
Pour étudier l’impact de la variable explicative “sécurité” perçue par les internautes, nous avons utilisé l’échelle de mesure relative à la sécurité/confidentialité issue de l’échelle de Netqual proposée par G. Bressolles en 2004 et reprise dans les travaux de Boyer A. et Nefzi A., qui mesure la sécurité ou la confidentialité (Boyer & Nefzi, 2008).
Cette échelle de mesure est constituée de 3 items que nous avons dû adapter à notre questionnaire en remplaçant le mot “site” par le mot “réseau”.
Concernant la variable de la confiance nous avons utilisé l’échelle de mesure proposée par Jarvenpaa et Tractinsky de 1999 (Allagui & Temessek, 2013) qui est composée de 4 items.
Cette échelle de mesure dont les propriétés psychométriques ont été jugées satisfaisantes a été utilisée dans la littérature existante.
Cette échelle de mesure est utilisée pour mesurer la confiance des utilisateurs envers un site. Nous l’avons donc adapté à notre étude en remplaçant le mot “site” par “réseau”.
Pour la variable “attitude envers l’achat” nous avons utilisé l’échelle de Cheung, Chang et Lai datant de 2000 (Zaoui, 2009) qui mesure l’attitude du consommateur envers l’achat sur internet.
Nous n’avons pas modifié ces items qui étaient en parfaite adéquation avec notre étude.
Concernant la variable relative à la satisfaction des consommateurs nous nous sommes orientés vers l’échelle de mesure de Llosa de 1996 (Allagui & Temessek, 2013) qui mesure la satisfaction par rapport à l’utilisation du site.
Cette échelle qui a été largement validée dans la littérature précédente a fait l’objet d’une modification dans notre étude.
Pour ce faire nous avons remplacé les mots “site” ou “site web” par le mot “réseau”.

Pour étudier le concept de fidélité nous avons décidé d’utiliser l’échelle deux des trois échelles de mesures développées dans l’article “La relation entre la perception de la qualité et la fidélité: Une application aux sites web commerciaux.” de Boyer A. et Nefzi A. (Boyer & Nefzi, 2008).
Dans leurs travaux, leur définition de la fidélité donne 3 dimensions qui correspondent à 3 échelles de mesure : la réclamation (4 items), l’intention de réachat (4 items) et le bouche-à- oreille (4 items) qui correspond à l’intention de recommandation.
Nous avons conservé seulement 2 des 3 dimensions pour mesurer la fidélité des consommateurs dans notre étude, à savoir l’intention de recommandation et l’intention de réachat car la réclamation n’était présente dans aucune autre littérature à notre connaissance.
À la suite de cette sélection nous avons dû remplacer une fois encore le mot “site” par “réseau” afin d’adapter les items sélectionnés à notre étude.
Nous avons proposé 28 questions qui correspondent chacune à l’un des 28 items différents de nos 6 échelles de mesure.
Les 28 questions proposées dans le questionnaire ont toutes été des questions à échelle en 7 points. Nous avons utilisé des échelles de Likert de 1 (=Pas du tout d’accord) à 7 (=Tout à fait d’accord).
Il en va de même pour l’échelle de mesure relative à l’attitude des consommateurs envers l’achat avec des échelles d’Osgood allant de 1 (= Irritant ; Déplaisant ; Désagréable ; Ennuyeux) à 7 (= Passionnant ; Plaisant ; Agréable ; Intéressant).
Les tranches d’âges du questionnaire ont été définies grâce à une source de Statista. (Source : Répartition des utilisateurs actifs de Facebook dans le monde en janvier 2019, par âge et sexe ; Statista).
Nous avons administré le questionnaire sur une période de 10 jours, du 24/03/2020 au 03/04/2020.
Le nombre de répondants au questionnaire est de 252.
Le choix de la population de l’échantillon est aléatoire avec les caractéristiques suivantes :
38,5% des répondants sont des femmes
61,5% des répondants sont des hommes
52,4% des répondants ont un âge compris entre 18 ans et 24 ans
21,8% des répondants ont un âge compris entre 25 ans et 34 ans
8,3% des répondants ont un âge compris entre 35 ans et 44 ans
8,7% des répondants ont un âge compris entre 45 ans et 54 ans
7,1% des répondants ont un âge compris entre 55 ans et 64 ans
1,6% des répondants ont un âge supérieur ou égal à 65 ans
Selon l’étude descriptive3 de l’échantillon on observe que la moyenne SEXE est de 1,38. Nous avons codé en valeur 1 pour les répondants de sexe masculin et 2 pour les répondants de sexe féminin.
En d’autres termes cela signifie que les répondants sont en majorité des hommes, avec 155 hommes et 97 femmes dans l’échantillon.
Concernant la statistique TRANCHE D’ÂGE la moyenne est de 2,01. Nous avons codé les tranches d’âges de 1 à 6 de la plus petite (18-24 ans) à la plus grande (+65ans).
Pour administrer le questionnaire le plus rapidement possible nous avons utilisé Google Form.
II. Proposition d’un modèle de recherche
Nous avons réalisé le modèle de recherche ci-dessous qui représente le schéma global de notre étude :
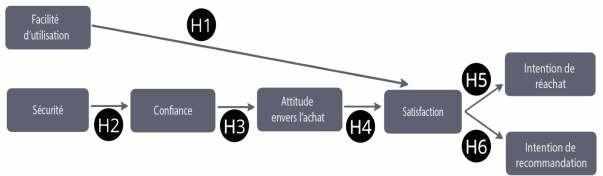
Notre modèle de recherche met en évidence 6 hypothèses. Les différentes variables ont été identifiées dans la revue de littérature.
Si l’ensemble des hypothèses sont vérifiées par la suite, ce schéma pourra être réutilisé dans le contexte d’une démarche marketing car le comportement du consommateur aura été préalablement étudié.
De plus, nous pourrons finalement déterminer si un internaute satisfait par le réseau est une personne susceptible de le recommander ou de racheter sur celui-ci.
Dans un premier temps, afin d’avoir une vision générale, nous réaliserons une analyse descriptive qui sera effectuée sur le logiciel SPSS Statistics, tout comme l’ensemble de nos analyses.
Dans un second temps, nous allons vérifier nos relations grâce aux analyses réalisées.
Tout d’abord, nous allons réaliser une étude préliminaire composée d’analyses factorielles et du calcul de l’alpha de Cronbach, ce qui nous permettra de valider les différentes variables. Par la suite, nous effectuerons des tests d’hypothèses dans le but de tester nos hypothèses de recherche.
Pour finir, nous pourrons valider ou non nos hypothèses par les résultats obtenus.
Dans troisième et dernier temps, nous réaliserons des analyses complémentaires grâce à d’autres variables : Homme / Femme et la tranche d’âge
Cela nous permettra d’analyser les comportements en fonction de nouveaux critères.
III. Validation des échelles de mesure
Nous avons récupéré une base de données constituée des réponses à notre questionnaire. Cette base a été modifiée et préparée afin d’obtenir une base de données brute.
II a donc été nécessaire de renommer nos variables de la manière suivante :
Facilité d’utilisation : FU
Sécurité : SECU
Confiance : TRUST
Attitude envers l’achat (AEA)
Satisfaction (SATIS)
Intention de réachat (IREACHAT)
Intention de recommandation (IRECO)
L’objectif de cette modification était de simplifier la lecture dans le logiciel d’analyse SPSS. De plus, nous avons coder les différents items. Prenons l’exemple de la facilité d’utilisation :
FU1_Ce site est facile à utiliser
FU2_Il est facile de rechercher sur le site
FU3_Il est facile de naviguer et de trouver ce que l’on recherche sur ce site
FU4_L’organisation et la mise en page de ce site facilitent la recherche d’informations
FU5_La mise en page de ce site est-elle claire et simple
Nous avons également inversé nos résultats dans notre base de données brute pour la variable : IREACHAT3_Je choisirai un site concurrent pour mon prochain achat
La première étape de l’analyse sera de déterminer les variables de notre modèle de recherche.
Pour cela, nous avons effectué une analyse factorielle du type ACP (Analyse en Composante Principale) pour chaque variable de notre modèle de recherche, afin d’obtenir un ACP finalisé.
Il faut alors interpréter l’indice KMO et vérifier s’il y a des crossloads.
Nous pourrons également en déduire si un ACP comporte une ou plusieurs composantes, en étudiant la matrice des composantes.
Il sera nécessaire d’étudier la matrice après rotation lorsqu’il y a plus d’une composante.
Pour donner suite à l’analyse factorielle, nous avons réalisé les tests de fiabilité pour chaque ACP, à l’aide du Test Alpha de Cronbach.
Ces différentes analyses déterminent les variables du modèle, tout en regroupant les questions qui ont une ressemblance.
IV. Procédure statistique de résolution des hypothèses
Afin de réaliser les tests d’hypothèses, nous avons utilisés des régressions linéaires simples car il s’agit de variables quantitatives pour l’ensemble de nos hypothèses.
Nous avons repris notre modèle de recherche comprenant nos différentes hypothèses.
Par exemple, une régression linéaire a été réalisée pour l’hypothèse 1, en sachant que la satisfaction dépend de la facilité d’utilisation.
L’analyse nous permettra d’obtenir, pour chaque hypothèse, un Sig Régression, un coefficient de régression et un résultat (c’est à dire savoir si l’hypothèse est validée ou rejetée).
V. Analyses complémentaires
L’objectif des analyses complémentaires est d’apporter une précision en fonction des variables choisies.
Ici, il s’agit d’un test ANOVA à 1 facteur permettant de comparer les moyennes.
Nous allons effectuer deux tests. Un premier en fonction du SEXE des répondants et un deuxième en fonction de la tranche d’âge.
Ces analyses nous permettront d’obtenir des graphiques et de comparer les moyennes.
______________________________________
1 Annexe 1 : Résumé des échelles de mesure
2 Annexe 2 : Questionnaire de l’étude
3 Annexe 3 : Analyses descriptives