L’analyse de la fidélité client – Etude empirique
Chapitre 2 Etude empirique
Dans ce chapitre, nous allons dans un premier temps expliquer le contexte de collecte des données utilisées dans notre étude.
En deuxième lieu nous allons évoquer la méthodologie utilisée pour étayer notre analyse.
En troisième lieu , nous ferons une synthèse des résultats obtenus et leur confrontation avec la littérature existante. Et nous terminerons par la formulation de quelques pistes de réflexion pour la poursuite de la présente étude.
Section 1 Collecte des Données
1.1 Contexte de l’étude
La situation exceptionnelle de crise sanitaire dans laquelle nous sommes aujourd’hui ne nous a pas permis de réaliser une collecte de données sur le terrain.
Dans ce contexte, nous avons opté d’utiliser le jeu de données « Telco-Customer-Churn » issu du site internet www.Kaggle.com10 et qui serait parfaitement adapté à la problématique étudiée dans le cadre de la présente étude.
Ce jeu de données avait été conçu en 2018 par la communauté de la société IBM 11 à dessein de permettre l’analyse du taux d’attrition d’une société B2C opérant dans les télécommunications. Ce jeu de données est en anglais et sa dernière mise à jour remonterait au 23/02/2018.
Dans une société de B2C, pour construire un tel jeu de données il suffirait d’identifier dans sa base client et ce sur une certaine durée les clients qui sont partis et ceux qui sont restés et de leur associer tous les attributs qui pourraient potentiellement expliquer leur comportement.
En l’occurrence notre jeu de données répertorie sur une durée d’un mois les clients qui sont partis ou restés dans la société des télécommunications ainsi qu’un certain nombre d’attributs que nous évoquerons plus loin.
La figure ci-après nous donne un aperçu du jeu de données.
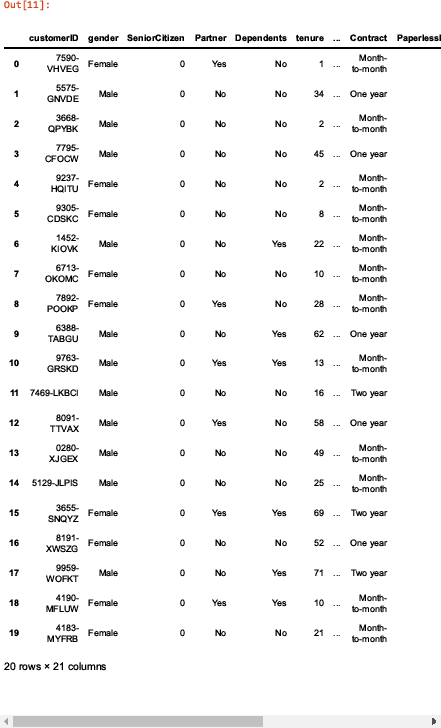
Figure 3: Aperçu jeu de données (Source Personnelle : implémentation python jupyter)
Dans cet aperçu chaque ligne représente un client unique et le jeu de données complet en compte 7043. Les colonnes qui représentent les attributs des clients sont au nombre de 21 dans le jeu de données complet et leurs caractéristiques sont décrits dans le dictionnaire des métadonnées suivant :
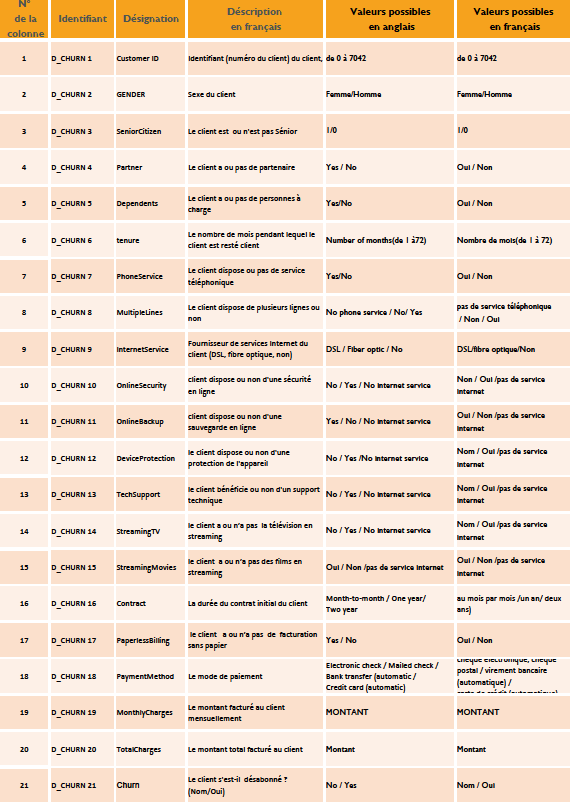
Figure 4: Dictionnaire des métadonnées (Source personnelle)
En résumé le jeu de données comprend:
- La colonne N° 1 correspondant à l’identifiant du client.
- La colonne N°21 (Churn) correspondant à l’attrition et indique si le client est parti (valeur Churn=’yes’) ou pas parti de la société (valeur Churn=’No’).
- Les colonnes du N°2 au N° 20 correspondent aux attributs des clients concernant : les services auxquels chaque client s’est abonné, les Informations sur le compte client, et des informations socio-démographiques.
La problématique de la présente étude appliquée à ce jeu de données serait d’intégrer le Machine Learning dans les programmes de fidélisation client de cette société dont l’objectif serait de baisser le taux d’attrition et la démarche que nous proposons dans ce cas d’espèce est de :
- Concevoir un modèle de Machine Learning pour la prédiction du Churn de la société.
- Procéder ensuite à une interprétation du modèle obtenu afin de déceler des insights, des comportements clients qui pourraient être des pistes de réflexion dans la construction des plans d’actions à intégrer dans un programme de fidélisation bien pensé.
Le jeu de données et la réponse à la problématique posée nous amène à étudier un cas de classification binaire en l’occurrence la segmentation des clients en ‘Churn’ (les clients qui pourraient partir de la société) et ‘No Churn’ (les clients qui pourraient rester) en utilisant la méthode d’apprentissage supervisé.
10 Jeu de données Telco_customer : https://www.kaggle.com/blastchar/telco‐customer‐churn
11 IBM Community: https://community.ibm.com/community/user/home
1.2 Méthodologie suivie
La méthodologie retenue est l’implémentation d’un algorithme de Machine Learning sous le langage de programmation Python dans Jupyter Notebook dont nous reprenons ici les étapes essentielles.
Pendant la préparation du jeu des données, on a réalisé les tâches suivantes :
- La modification du format de données de la variable explicative « Montant total facturé au client » d’un type catégoriel a un type numérique.
- La Modification du format de données de la variable explicative « SeniorCitizen » d’un type numérique a un type catégoriel.
- La création d’une nouvelle variable explicative ‘averagecharges’ qui est la moyenne des dépenses mensuelles.
- Suppression des variables (‘customerID’,’MonthlyCharges’,’TotalCharges’).
- Encodage des variables qualitatives.
1.2.1 Analyse exploratoire du jeu des données
1.2.1.1 Imputation des variables nulles
Le jeu de données ne contient que 11 valeurs nulles (NAN) qui sont toutes dans la colonne « TotalCharges » et correspondent aux clients dont la variable « durée de vie dans l’entreprise» est égale à zéro. Il est clair que les clients qui ne restent pas dans l’entreprise ne dépensent pas, nous pouvons donc les supprimer du jeu de données sans risque.
1.2.1.2 Variable cible
La variable cible, celle que nous allons analyser et sur laquelle va porter la prédiction de notre algorithme de Machine Learning est la variable ‘Churn’.
L’analyse de la répartition des clients du jeu de données selon le ‘Churn’ nous donne le résultat suivant
- Clients ‘No Churn’: 0.73%
- Clients ‘Churn ‘ : 0.27%
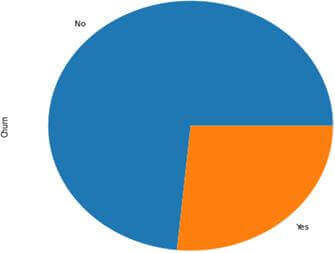
Figure 5 : Répartition des clients selon le Churn
Ce résultat nous indique que le taux d’attrition dans cette société sur un mois aurait été de 27% : Sur 1 mois 27% des clients de cette société auraient fait défection. Si nous étions patron de cette société, l’objectif de notre programme de fidélisation serait peut- être de baisser ce taux de Churn à moins de 10%.
1.2.1.3 Variables explicatives
Le jeu de données contient 18 variables explicatives parmi lesquelles 16 sont de type qualitatif et 2 sont de type quantitatif.
Parmi les 16 variables qualitatives nous distinguons :
- 6 variables binaires avec des valeurs uniques possibles Y/N ou 1/0.
- 9 variables avec 3 valeurs uniques possibles.
- 1 variable avec 4 valeurs uniques possibles.
Dans ce qui suit, nous allons visualiser les relations entre ces variables explicatives et la variable cible :
Relation entre la variable ‘Averagecharges ‘ et le ‘Churn’
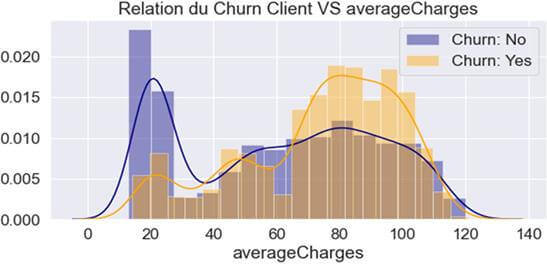
Figure 6 : Relation Churn & « averagecharges »
Ce graphique nous indique ceci :
- Avec une valeur de ‘averagecharges ‘ comprise entre 0 et un peu moins de 40 $ les clients seraient plutôt « fidèles » à la société (Courbe bleue au-dessus de la courbe orange).
- Avec une valeur de ‘averagecharges ‘comprise entre à peu plus de 60 et à peu près 115$ les clients seraient plutôt « infidèles » à la société.
Relation entre la variable ‘Tenure ‘ et le ‘Churn’
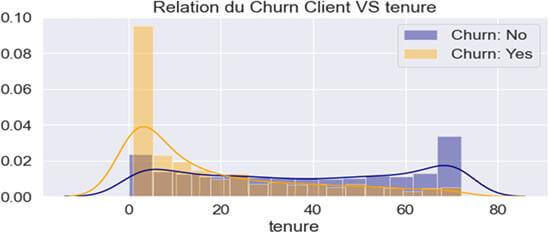
Figure 7 : RELATION CHURN & « Tenure »
Ce graphique nous indique qu’au-delà de 20 mois de présence dans la société les clients auraient plutôt légèrement tendance y à rester (Courbe bleue au-dessus de la courbe orange).
Relation entre la variable ‘SeniorCitizen ‘ et le ‘Churn’
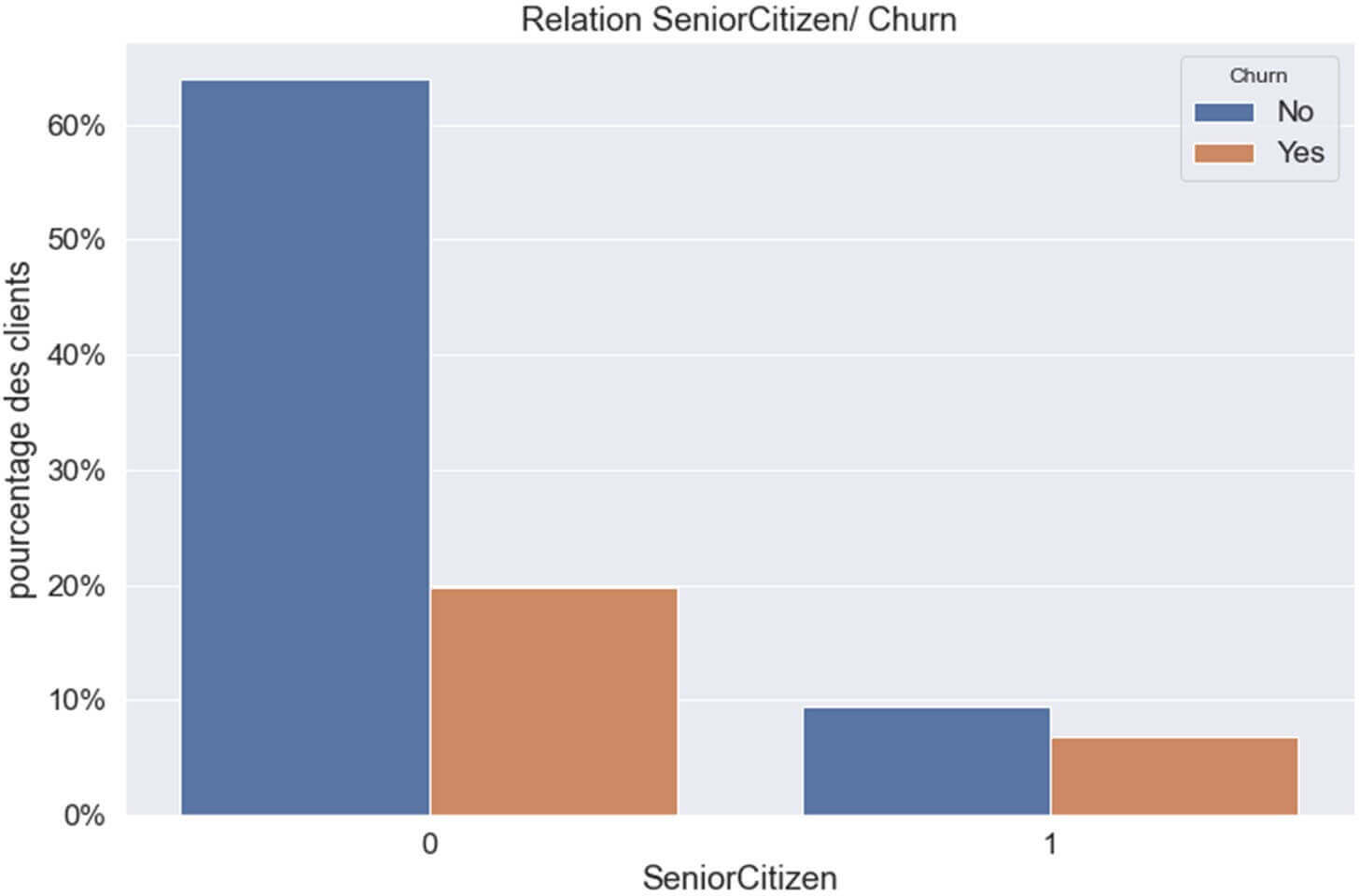
Figure 8 : RELATION CHURN & « SeniorCitizen »
Ce graphique nous indique que le fait qu’un client soit jeune (variable ‘SeniorCitizen’=0) le rendrait plus « fidèle » à la société.
Relation entre la variable ‘Gender ‘ et le ‘Churn’
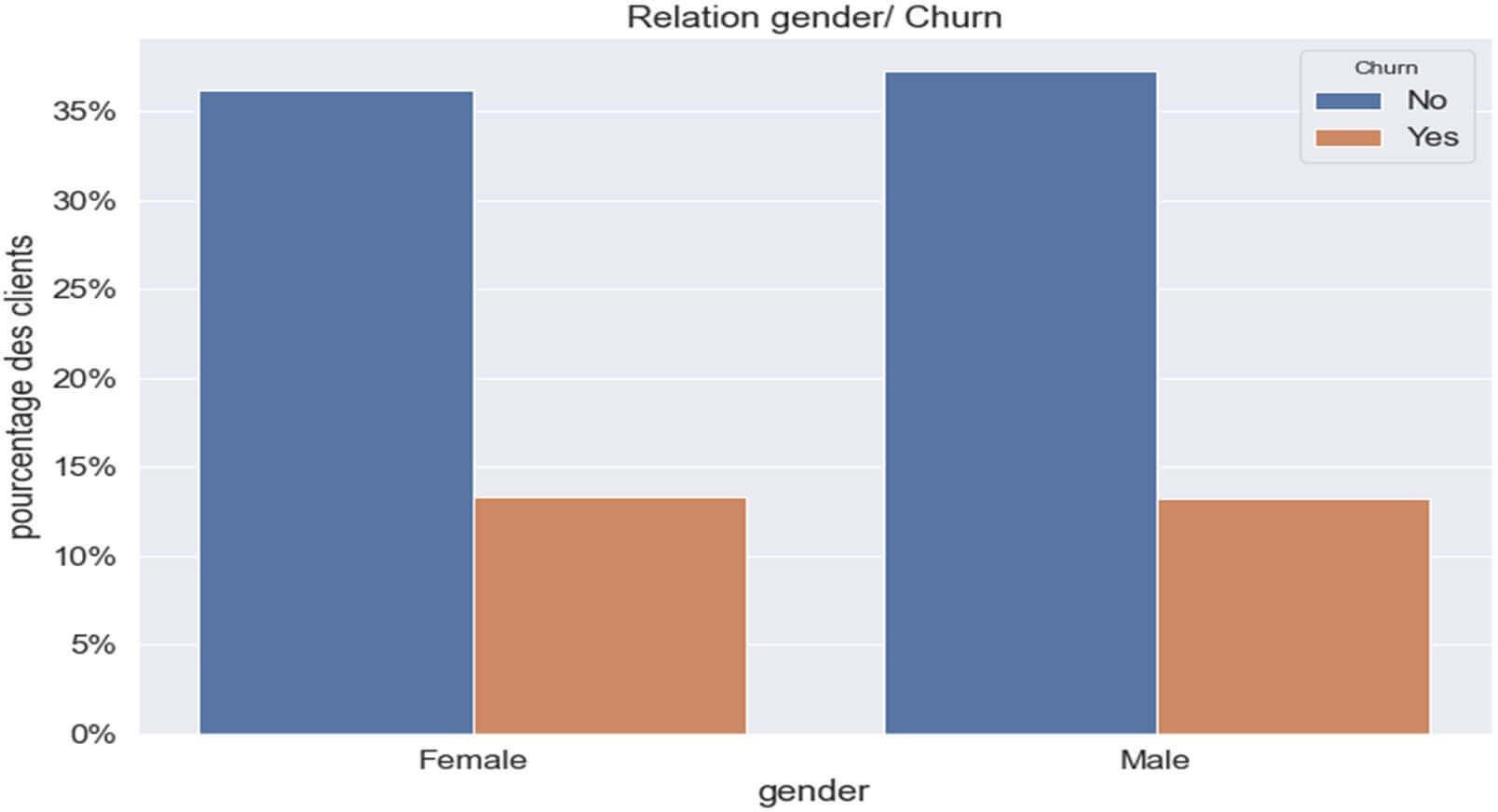
Figure 9 : RELATION CHURN & « Gender »
Ce graphique nous montre que le sexe n’aurait pas d’impact sur la fidélité client.
Relation entre la variable ‘Partner ‘ et le ‘Churn
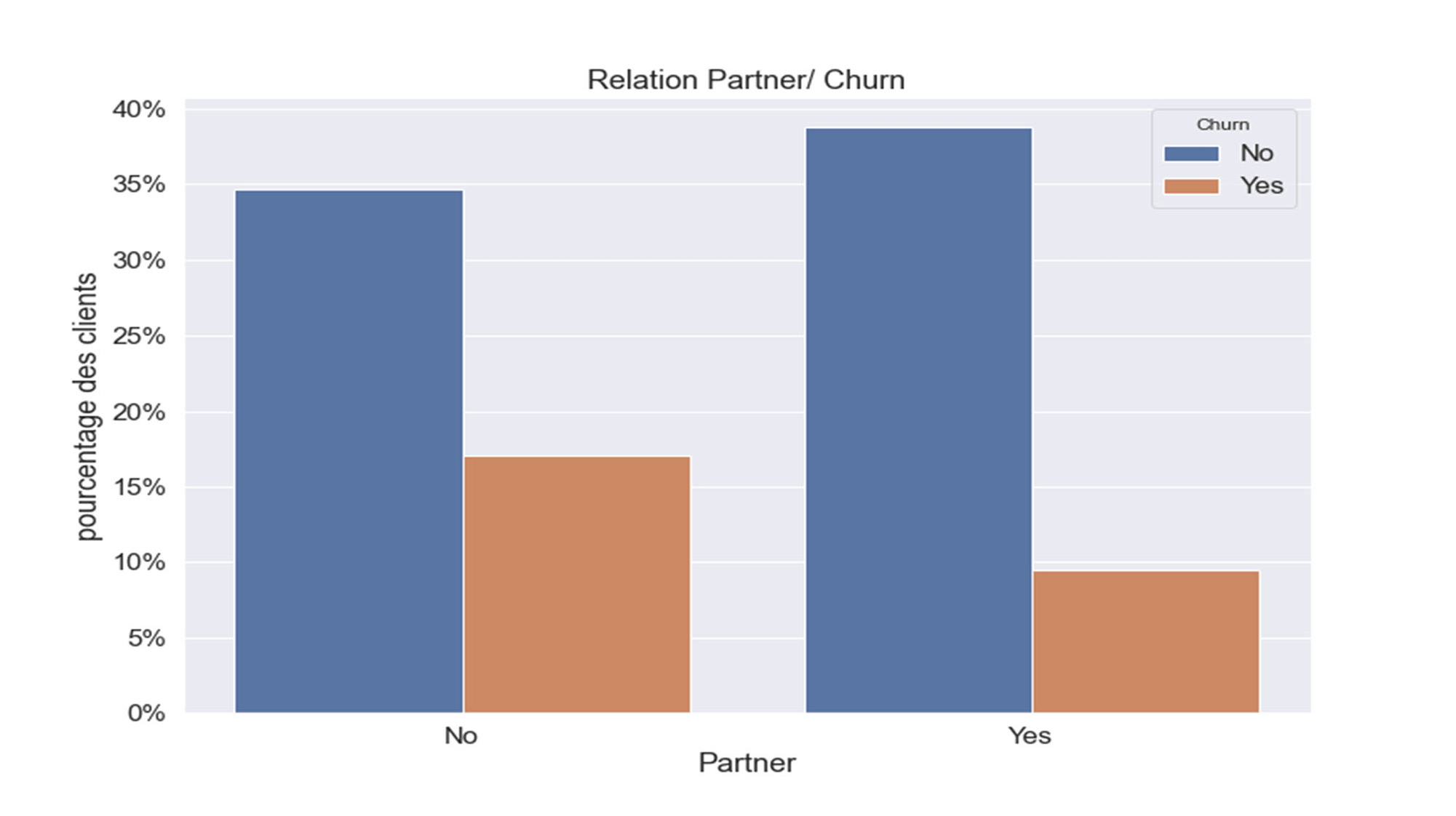
Figure 10 : RELATION CHURN & « Partner »
Ce graphique nous indique qu’en moyenne le client sans partenaire (variable ’Partner’ =0) serait moins « fidèle » à la société qu’un client avec partenaire.
Relation entre la variable ‘Dependents ‘ et le ‘Churn’
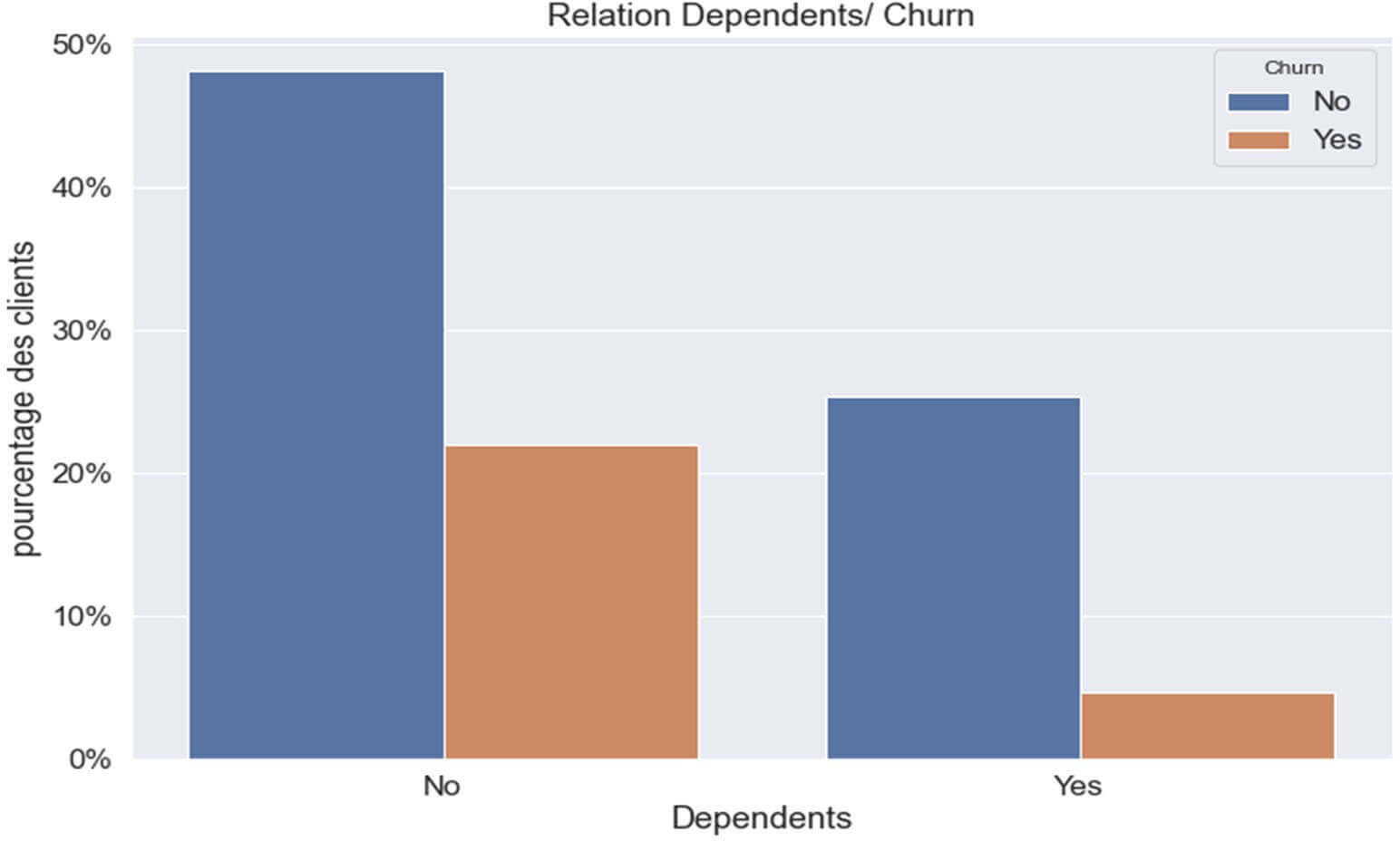
Figure 11: RELATION CHURN VS « dependents
Ce graphique nous indique que les clients sans personne à charge (‘Dependents’=No) seraient plus « fidèles » à la société que les clients avec des personnes à charge.
Relation entre la variable ‘MultipleLines ‘ et le ‘Churn’
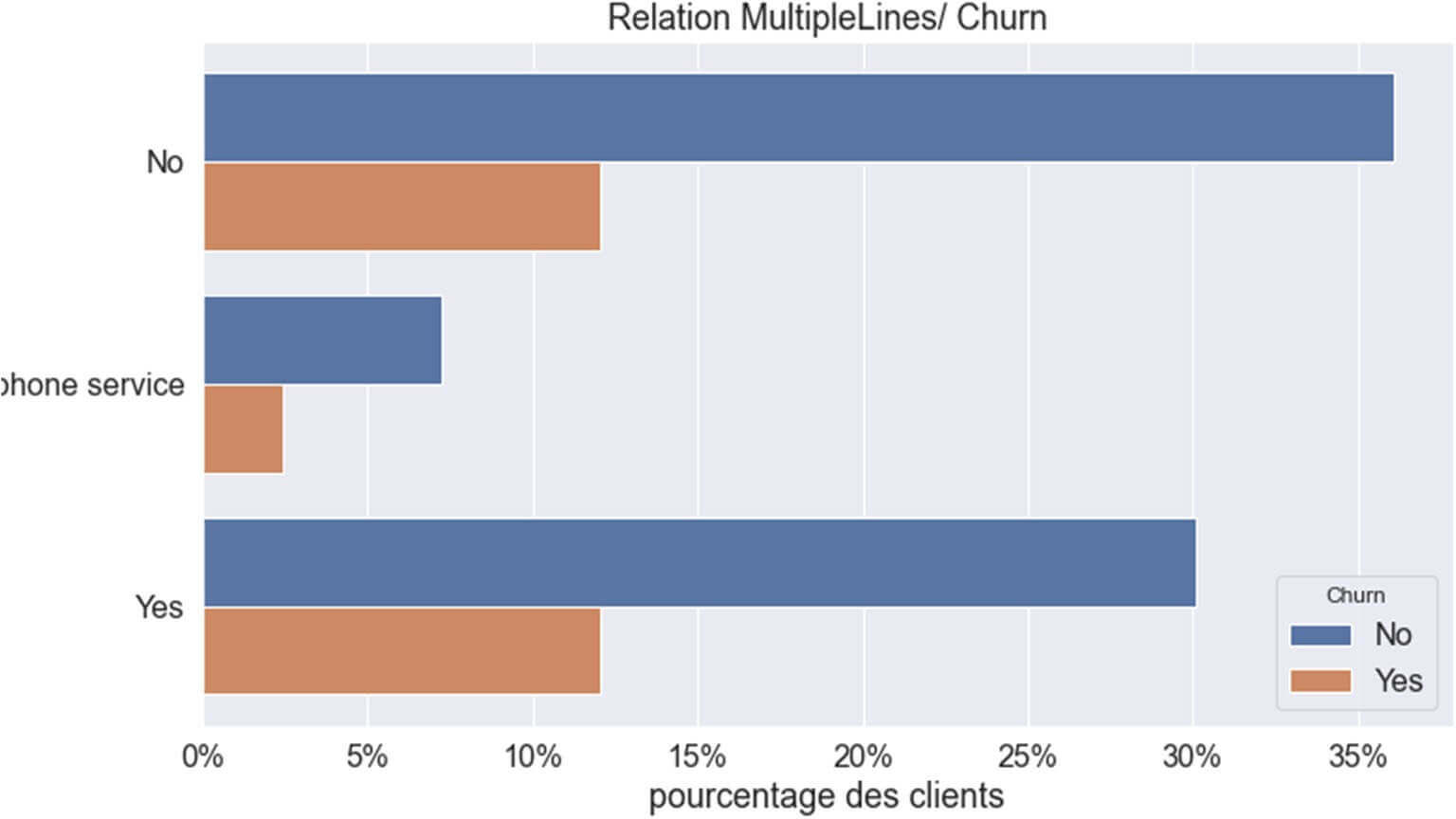
Figure 12 : RELATION Churn & « MultipleLines »
Ce graphique nous indique qu’en général un client qui n’a pas souscrit à un service ‘MultipleLines’ serait plus « fidèle » à la société.
Relation entre la variable ‘InternetService‘ et le ‘Churn’
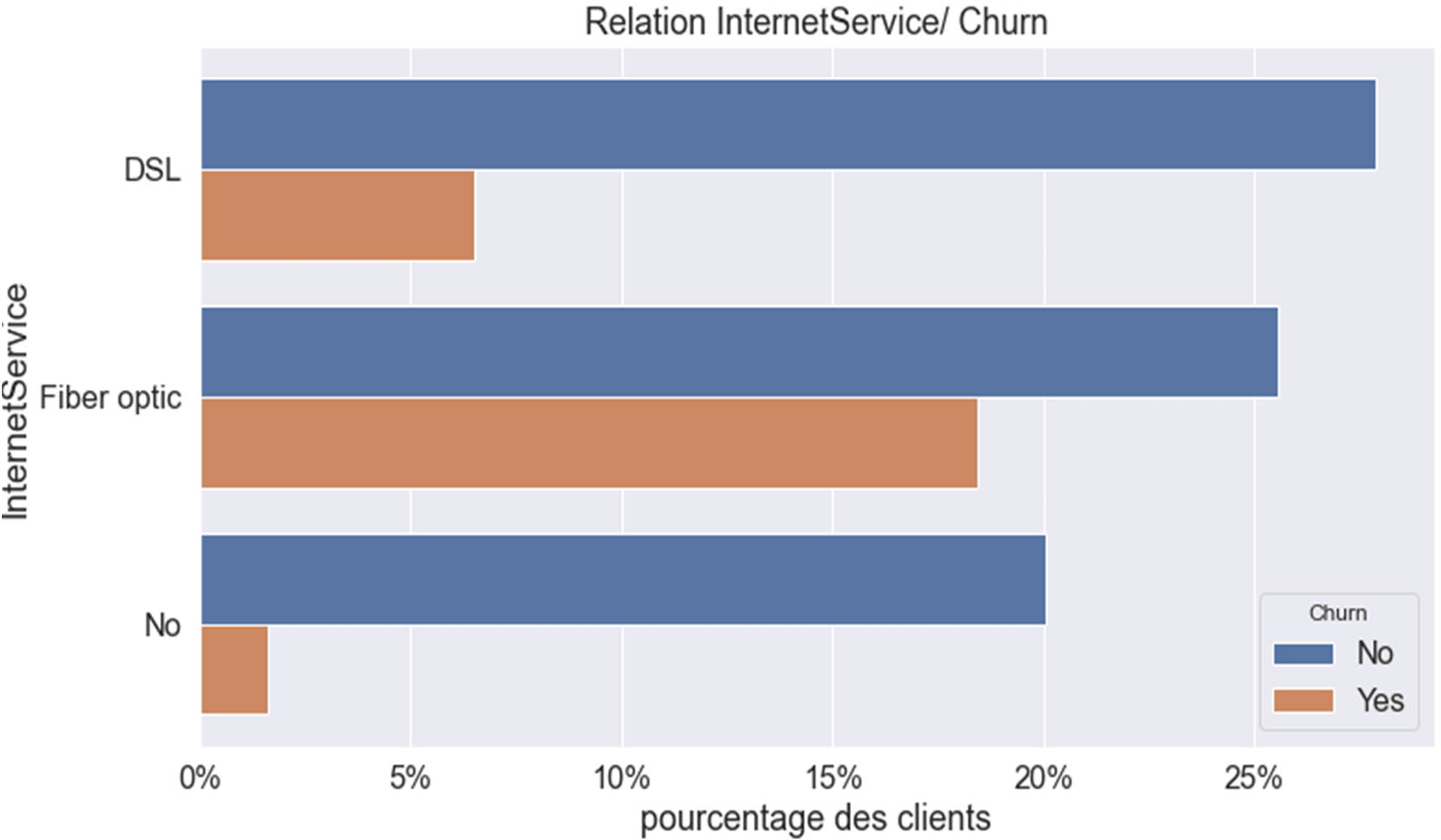
Figure 13 : RELATION CHURN & « Internet Service »
Ce graphique nous indique qu’en général les clients disposant d’un ‘Internet Service’ de type « Fiber optic » seraient plutôt « infidèles à » à la société.
Relation entre les variables ‘Contract ‘ et le Churn
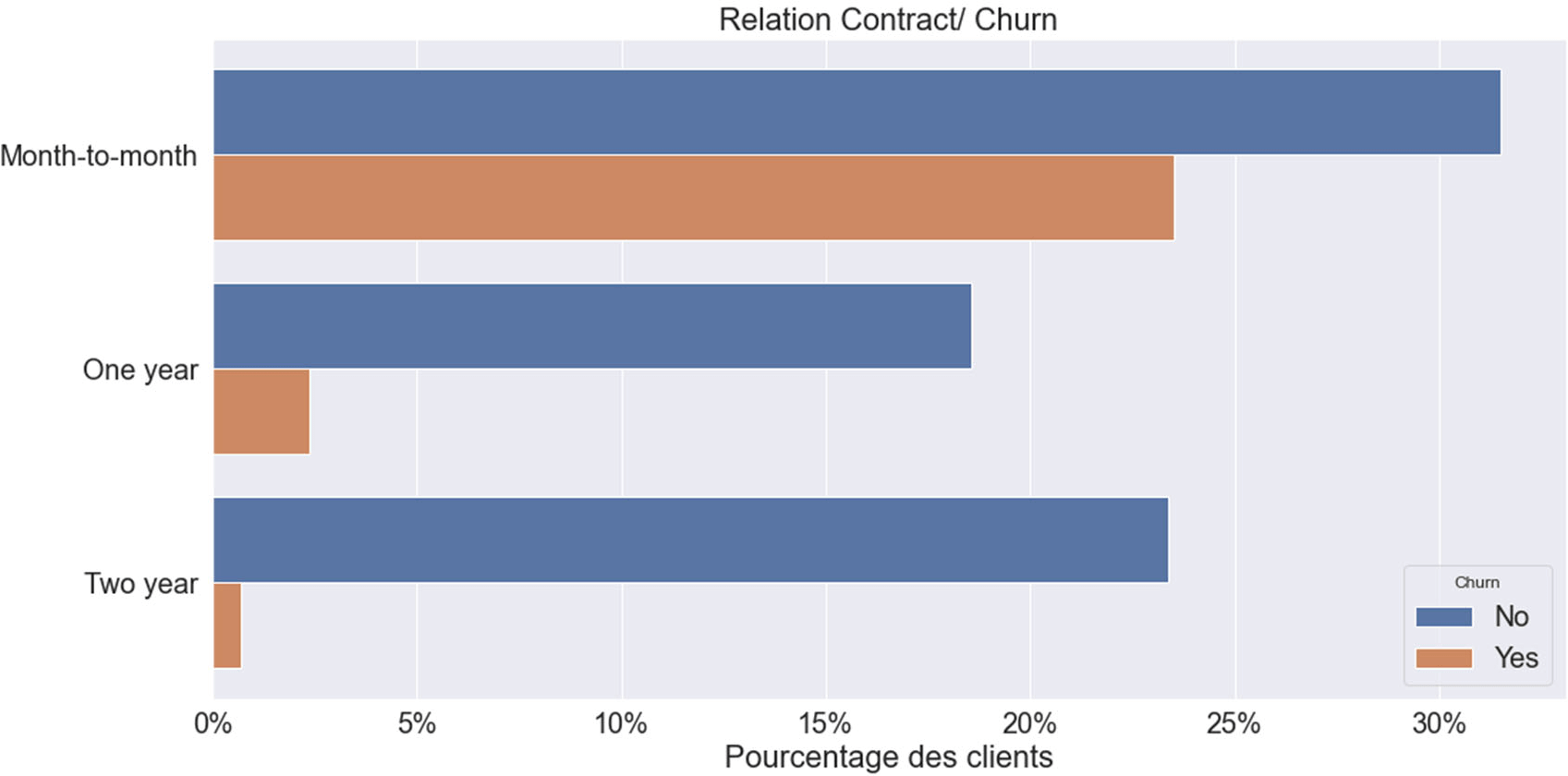
Figure 14 : RELATION CHURN & « Contract »
Ce graphique nous indique que les clients avec un petit contrat de base (‘Month-to- month’) seraient les moins « fidèles » alors que les clients avec un contrat de base de 2 ans (‘Two year’) seraient plus fidèles. Ces derniers en sont peut être contraints par des clauses rigides se trouvant dans le contrat.
Les variables (‘’OnlineSecurity’, ‘OnlineBackup’, ‘DeviceProtection’, ‘TechSupport’, ‘StreamingTV’, ‘StreamingMovies’) sont des services optionnels proposés à des Clients disposant d’une offre internet. Nous allons visualiser la relation groupée de Ces variables avec le Churn.
Relation entre les variables des services optionnelles à internet et le ‘Churn’
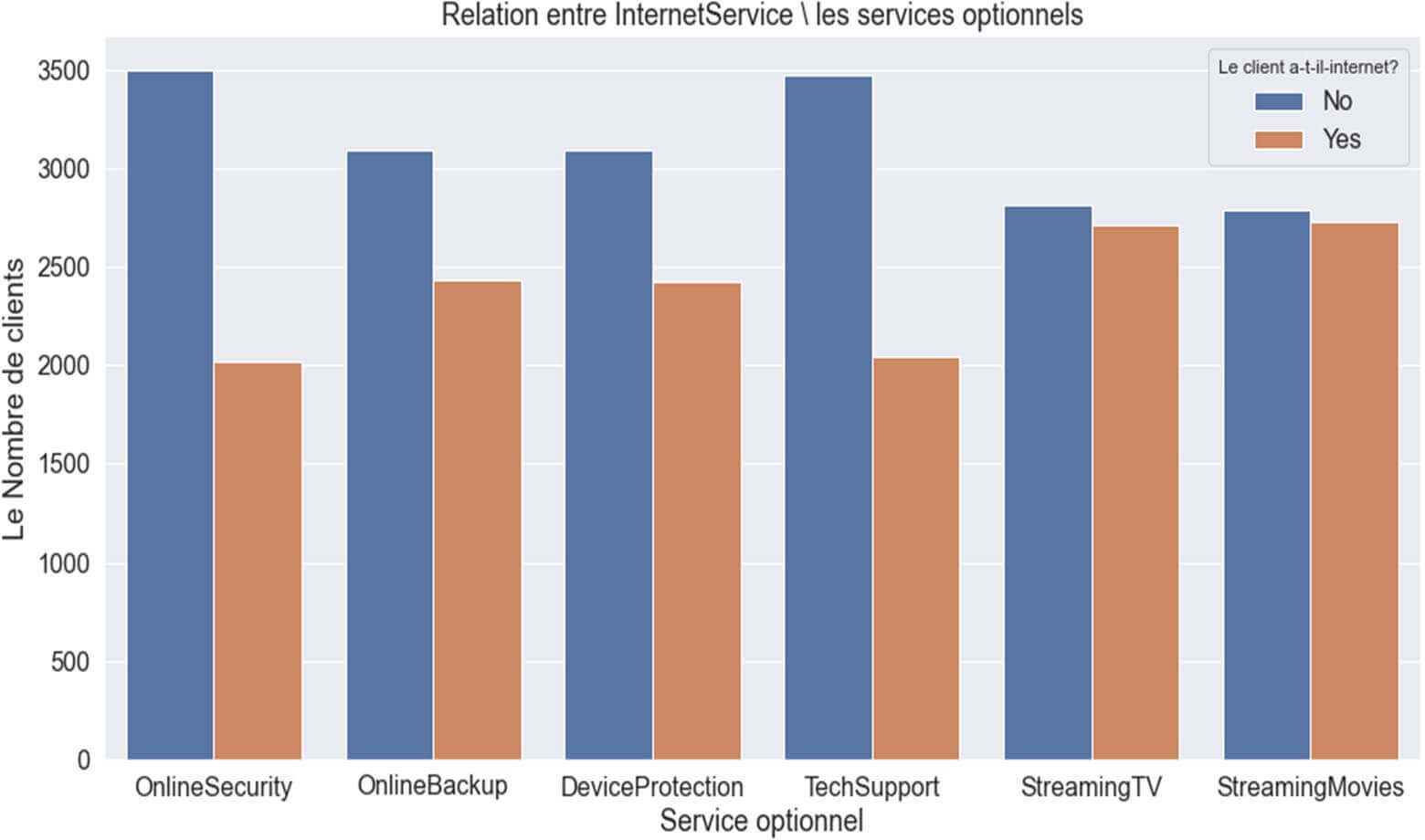
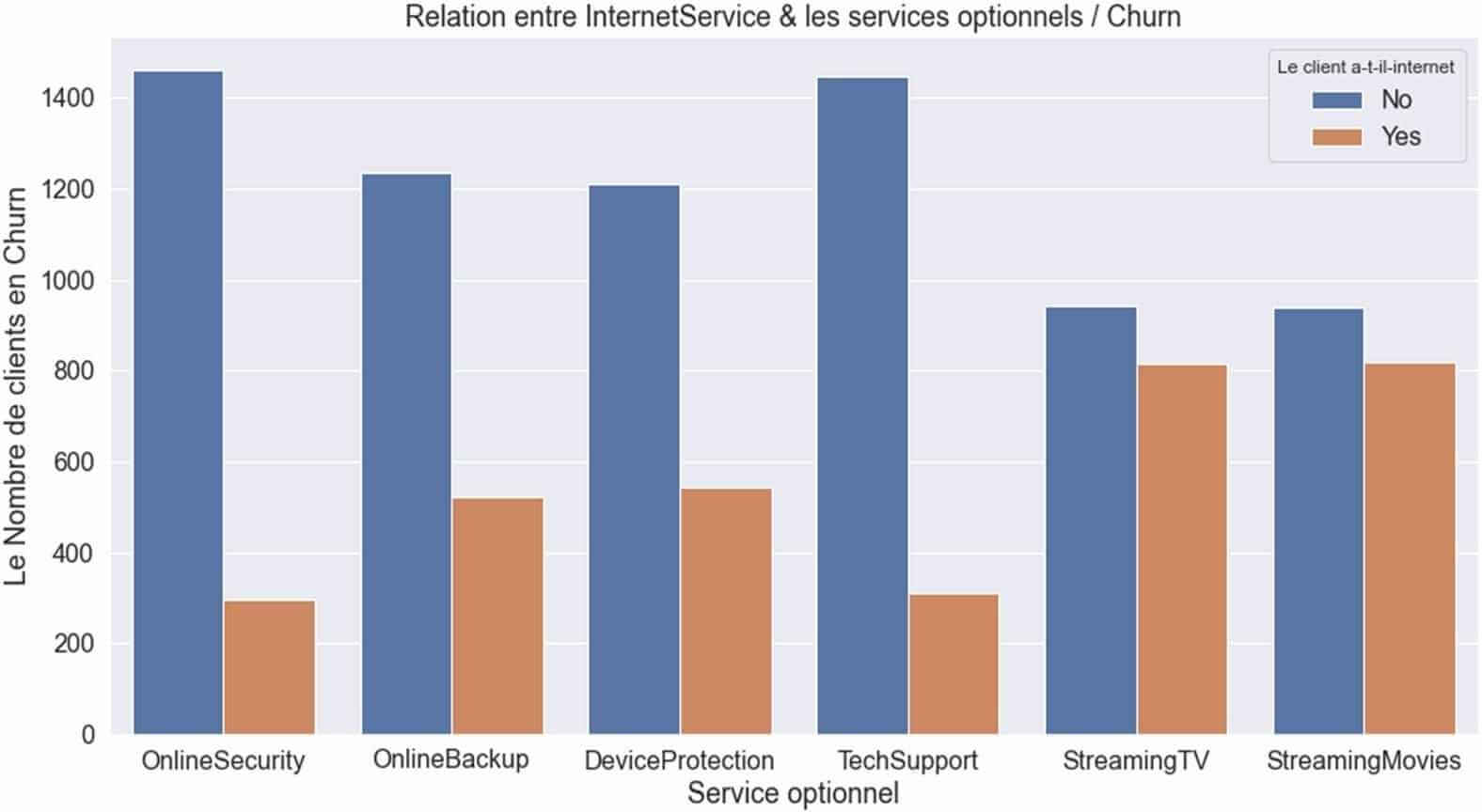
Figure 15: RELATION CHURN & « service internet optionnel »
Ce graphique nous indique que globalement :
- Il y aurait beaucoup plus de clients sans abonnement internet (Zones en bleue) que des clients avec abonnement internet.
- Les clients sans abonnement internet seraient plus « infidèles » que les clients avec abonnement internet
Relation entre ‘Contract ‘, ‘averagecharges’,’PaymentMethod’ et le Churn
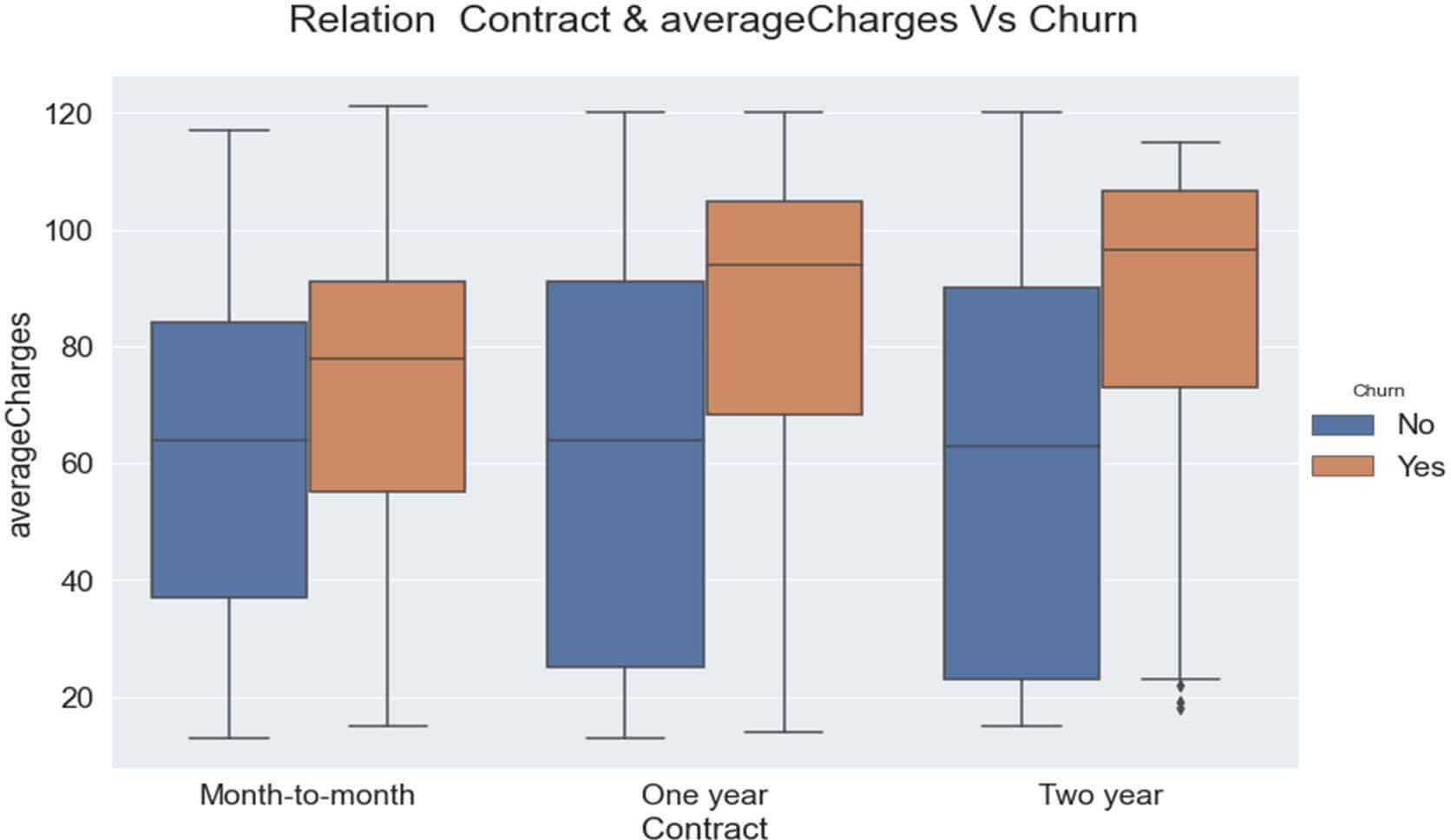
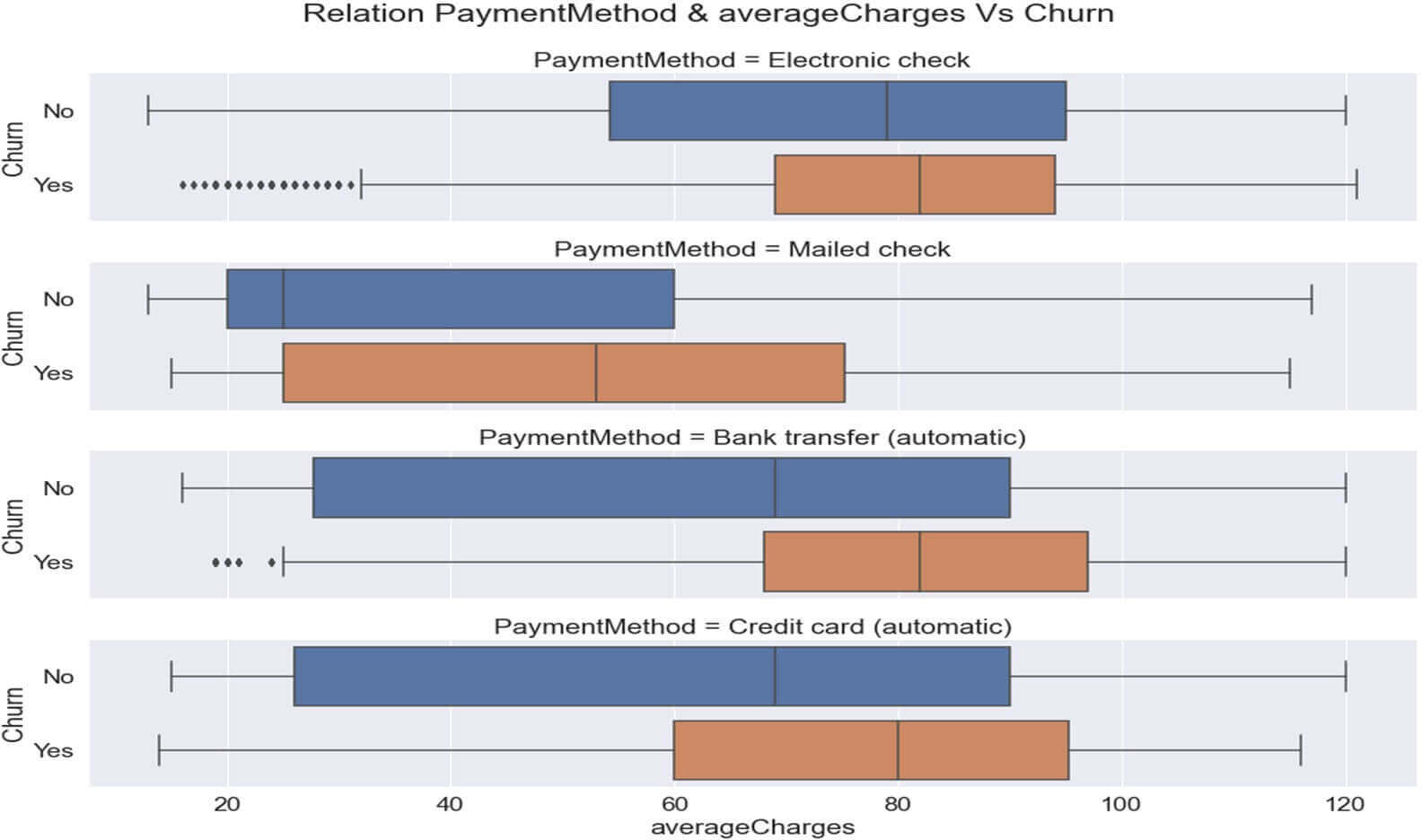
Figure 16: RELATION CHURN & « AVERAGESCHARGES & « CONTRACT »& »PaymentMethod »
Ce graphique nous indique qu’il y aurait :
- Une forte concentration de clients « fidèles » parmi les clients avec un contrat de base d’au moins un an et payant des charges mensuelles moyennes comprises entre 30 et 90 $.
- Une forte concentration de clients « fidèles » parmi les clients payant des charges mensuelles moyennes comprises entre 30 et 90 $ en mode ’ Bank Transfer (automatic)’ ou ‘ Credit card (automatic)’.
Relation entre les variables ‘PaymentMethod ‘ et le Churn
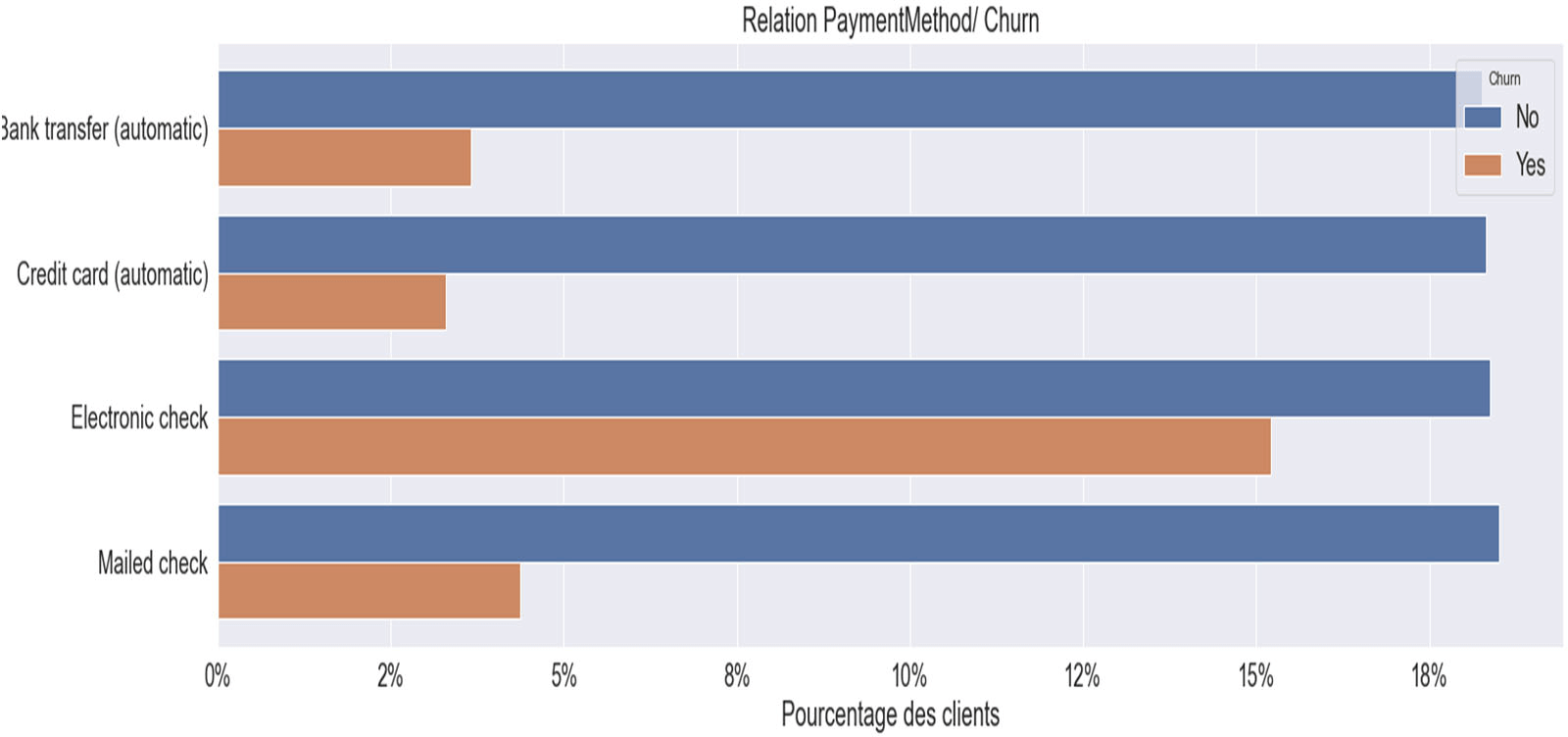
Figure 17 : Relation CHURN & « PaymentMethod »
Ce graphique nous indique que les clients payant en mode de paiement ‘electronic check’ détiendraient un taux de Churn élevé.
Corrélation entre toutes les variables explicatives
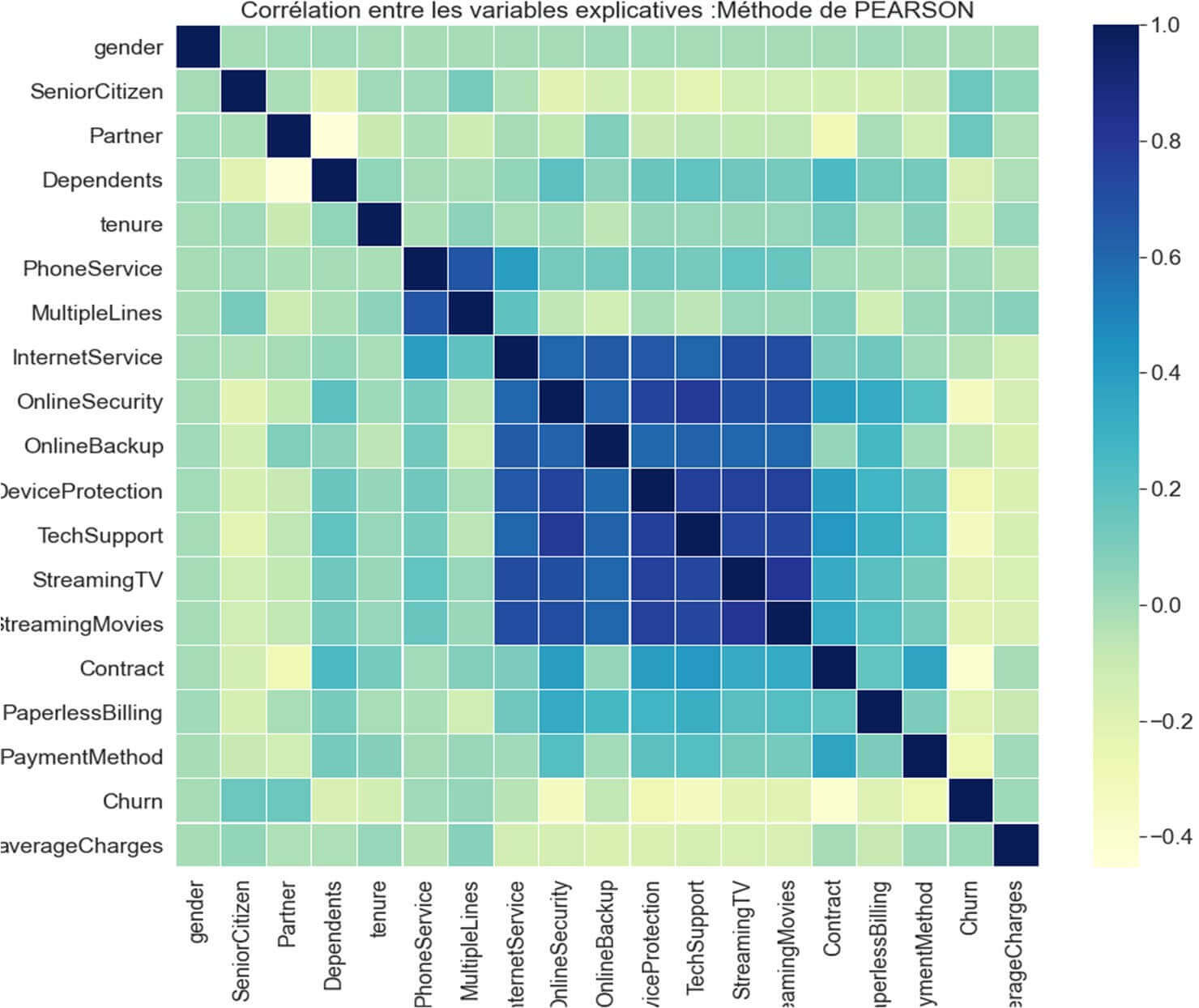
Figure 18 : Corrélation entre les variables explicatives
Le graphique ci-dessus nous montre une corrélation linéaire entre les variables explicatives (‘InternetService’, ‘OnlineSecurity’, ‘OnlineBackup’, ‘DeviceProtection’, ‘TechSupport’, ‘StreamingTV’, ‘StreamingMovies’) c-a- d entre le fait de souscrire un abonnement Internet et les services optionnels qui vont avec.
A ce stade, l’analyse exploratoire du jeu de données nous a permis de mettre en évidence des Insights, des explications sur certains comportements des clients relatives à leur fidélité vis -à-vis de la société.
Cependant, ces analyses portent sur les clients qui seraient déjà partis de la société (ceux pour lesquels la valeur du Churn=’Yes’) ou les clients actuels, restés dans la société (ceux pour lesquels la valeur du Churn=’No’).
Les insights sur les clients partis pourraient permettre de comprendre leur Churn et d’anticiper le futur comportement des clients qui sont restés. Les insights sur les clients qui sont restés pourraient aider à mieux les comprendre et de renforcer ainsi leur fidélité.
Dans ce qui va suivre nous allons aller plus loin dans notre démarche par l’entrainement d’un algorithme d’apprentissage automatique qui puisse :
- Prédire le comportement des clients restés pour contrecarrer le mieux que possible leur envie de départ.
- Prédire le comportement des futurs clients sur la base de l’analyse des comportements des clients partis et restés.
1.2.2 Entrainement du modèle
Pour l’entrainement du jeu de données nous avons choisi RandomForest et XGBoost qui comptent parmi les algorithmes de Machine Learning les plus performantes.
Le RandomForest et le XGBoost sont tous les deux des algorithmes dites d’Ensemble Learning basés sur les arbres de décision mais différent l’un de l’autre par leur technique d’apprentissage.
RandomForest utilise la technique du BAGGING qui consiste à entrainer plusieurs copies d’un même modèle, en l’occurrence un modèle d’arbre de décisions, sur une portion aléatoire des données (en échantillonnant le Dataset par Bootstrapping).
XGBoost utilise la technique du Boosting qui consiste à construire des modèles les uns après les autres en demandant à chaque modèle de corriger les erreurs de son prédécesseur.
Les résultats de l’entrainement et de l’évaluation des deux modèles sont synthétisés dans ce qui suit :
——————————————————————
Entrainement et évaluation du modèle : RandomForest
——————————————————————
[[187 19]
[ 29 46]]
precision — recall — f1-score — support
0 — 0.87 — 0.91 — 0.89 — 206
1 — 0.71 — 0.61 — 0.66 — 75
| accuracy | 0.83 | 281 | ||
| macro avg | 0.79 | 0.76 | 0.77 | 281 |
| weighted avg | 0.82 | 0.83 | 0.83 | 281 |
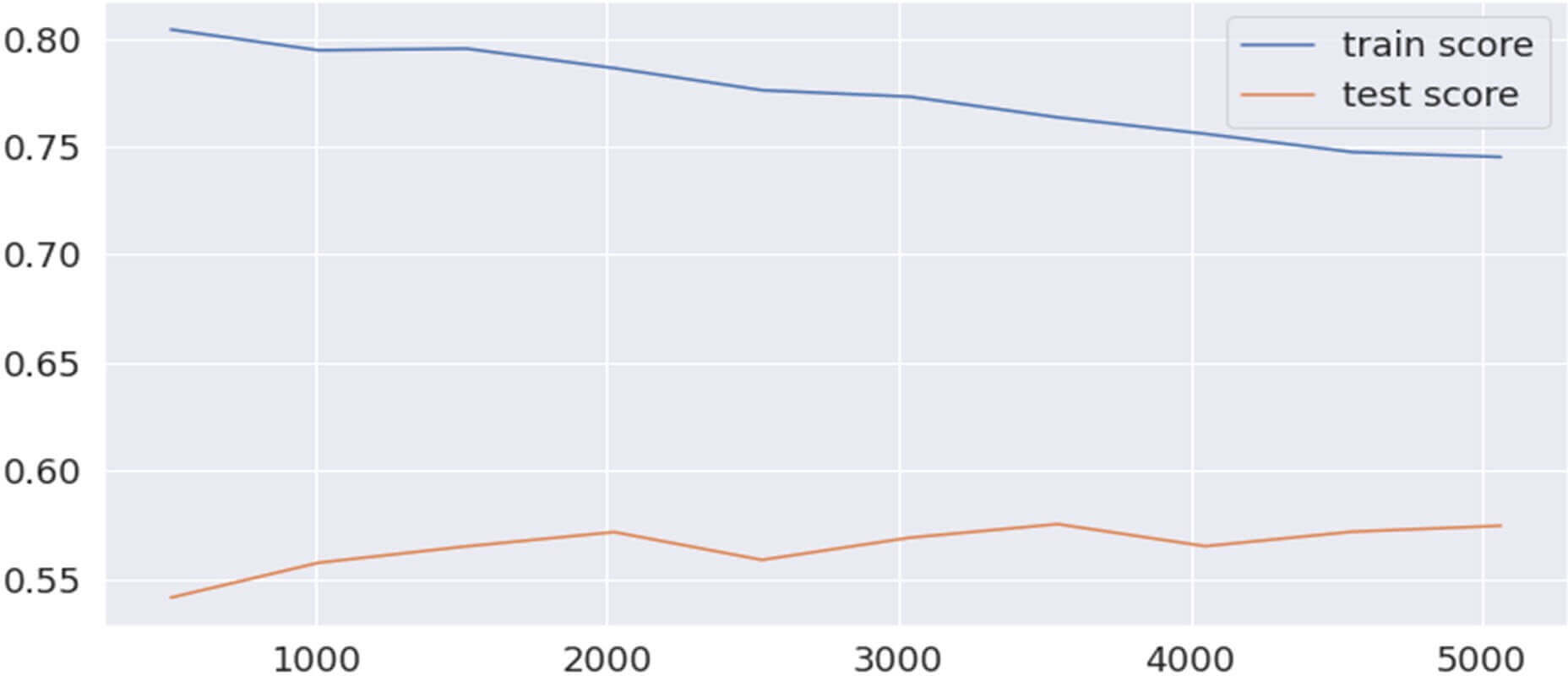
Figure 19: Entrainement et évaluation du modèle RandomForest
Ce visuel nous indique que le RandomForest nous a donné un f1-score de 0.83. Ce qui veut dire que dans la vie réelle, grâce au modèle, nous pourrions prédire avec une précision de 83% (83 cas sur 100) le comportement d’un client relatif à son attrition vis-à-vis de la société.
Cependant le modèle souffre peut-être d’un problème de surapprentissage (Overfitting en anglais) matérialisé par le fait que la ligne bleue soit beaucoup trop au-dessus de la ligne rouge.
Le surapprentissage d’un modèle c’est quand le modèle s’est beaucoup trop calibré sur un jeu de données et perdant ainsi tout sens de généralisation. En d’autres termes, notre modèle ne pourrait peut -être nous donner que des bien piètres résultats dans vraie vie.
————————————————————–
Entrainement et évaluation du modèle : XGBOOST
————————————————————-
[[182 24]
[ 30 45]]
precision recall f1-score support
0 0.86 0.88 0.87 206
1 0.65 0.60 0.63 75
| accuracy | 0.81 | 281 | ||
| macro avg | 0.76 | 0.74 | 0.75 | 281 |
| weighted avg | 0.80 | 0.81 | 0.81 | 281 |
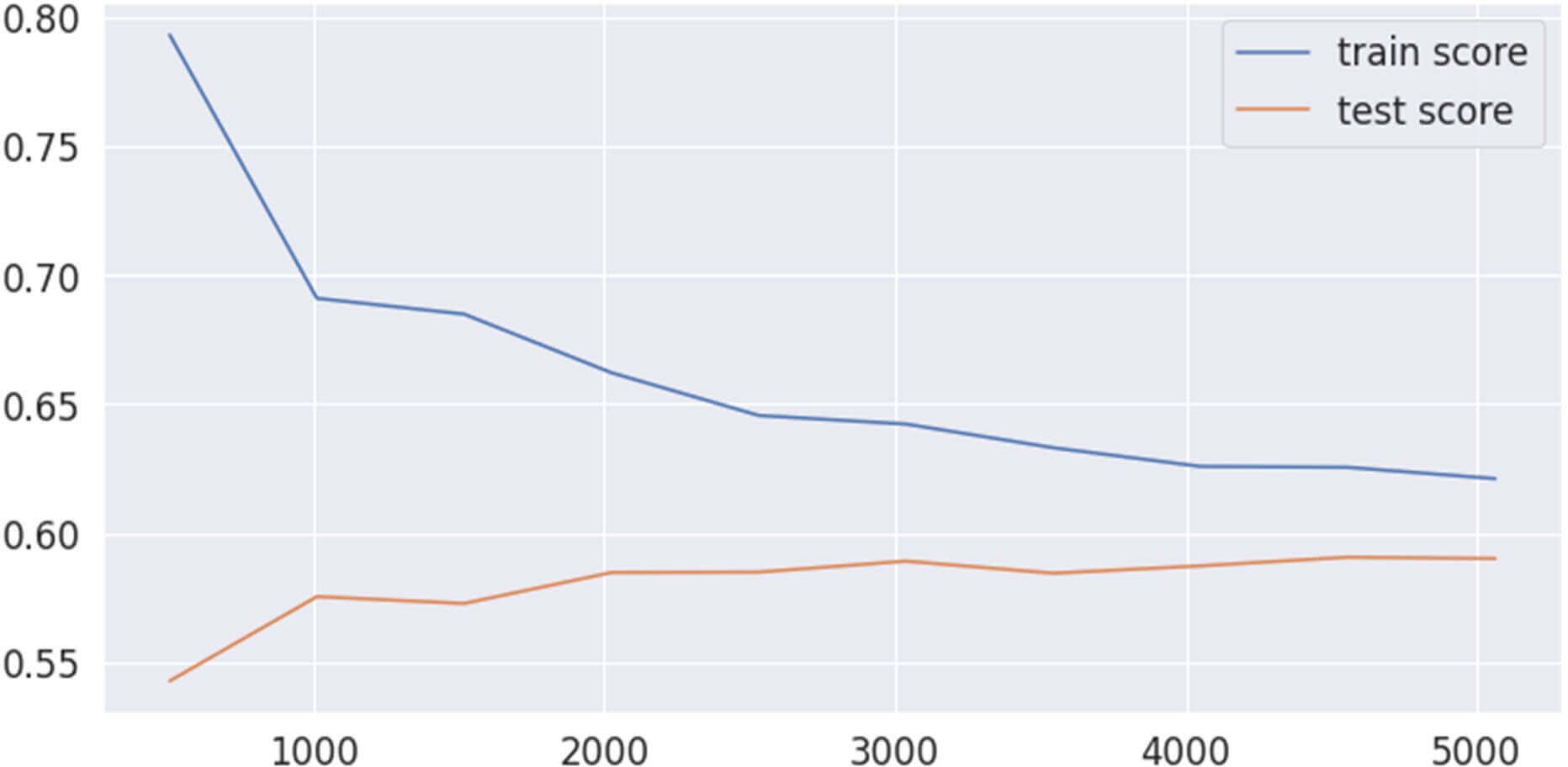
Figure 20 : Entrainement et évaluation du modèle XGBoost
Ce visuel nous indique que l’algorithme XGBoost nous a donné un f1-score de 0.81 donc moins précis que le 0.83 obtenu avec le RandomForest.
En revanche le fait que l’écart entre la ligne bleue et la ligne rouge évolue en décroissant est le signe que sur notre jeu de données le XGBoost garde son sens de généralisation et pourrait peut-être, dans la vraie vie, nous donner des bien meilleures performances que le RandomForest.
L’étape qui suit va nous permettre de valider notre choix de modèle à utiliser.
1.2.3 Validation du modèle
Pour nous aider à choisir entre les deux modèles nous allons tester leur robustesse(capacité à généraliser) avec la technique du Cross-Validation et aussi procéder à la comparaison de leurs performances avec le test de Wilcoxon.
Les résultats obtenus sont synthétisés dans ce qui suit.
——————————————————————————-
Intervalle de confiance 95 % :
RandomForest : [0.50760046 0.66847838]
Xgboost : [0.53919414 0.67507661]
WilcoxonResult (statistic=88.0, pvalue=0.07648946089689826)
——————————————————————————-
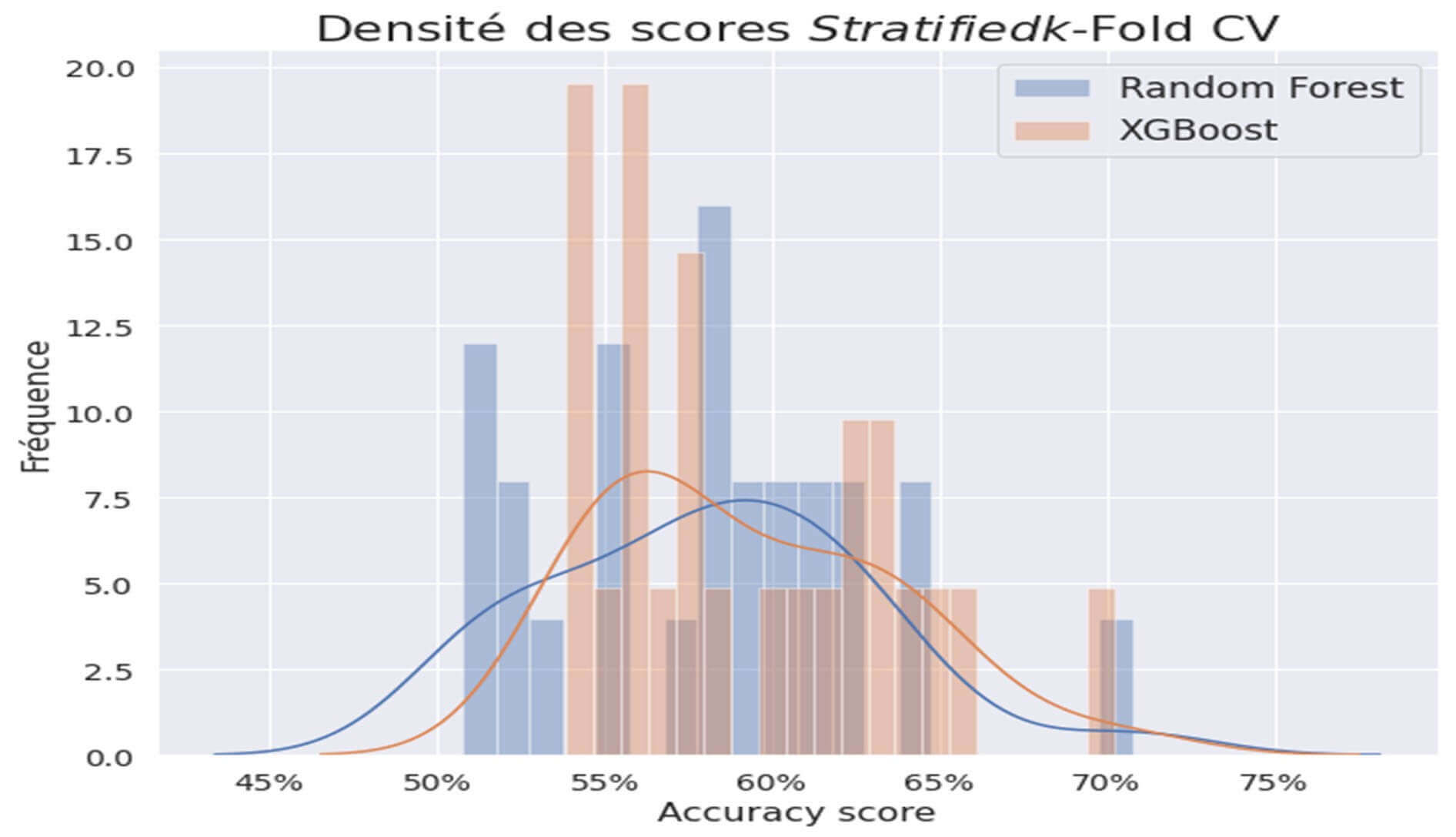
Figure 21: Validation de modèle XGBoost Vs RandomForest
Ce visuel nous indique ceci :
- Le résultat du test de Wilcoxon (pvalue=0.07648946089689826) signifie que l’hypothèse selon laquelle les distributions des deux modèles seraient identiques peut être validée à tort avec une probabilité de seulement 7,6%. En d’autres termes les deux modèles ne seraient pas identiques dans leurs performances.
- La courbe en bleue (RandomForest) est légèrement plus étalée à droite que la courbe en rouge (XGBoost). Ce qui veut dire que le RandomForest serait légèrement plus performant que le XGBoost.
- L’intervalle de confiance empirique nous indique que dans 95% de cas, le f1-score serait compris entre 0.50760046 et 0.66847838 pour le RandomForest et entre 0.53919414 et 0.67507661 pour le XGBoost. Cela veut dire que le modèle XGBoost serait légèrement plus stable, plus robuste que le RandomForest.
Finalement nous allons choisir le XGBoost qui, certes moins performant que le RandomForest, semblerait plus robuste. Dans l’étape qui va suivre nous allons procéder à l’interprétation du modèle XGBoost.
1.2.4 Interprétation du modèle
Pour l’interprétation de notre modèle XGBoost nous allons utiliser la méthode dite des valeurs SHAP. Cette méthode basée sur la théorie des jeux va nous permette de mesurer la contribution positive ou négative de chaque variable explicative dans la prédiction du Churn.
En matière d’interprétation d’un modèle, il convient de distinguer son interprétabilité (interprétation globale) et son explicabilité (interprétation locale)
1.2.4.1 Interpretabilite du modele
Nous allons ici analyser par le biais d’un certain nombre de graphiques l’impact globale des variables explicatives sur le Churn.
1.2.4.1.1 G Graphique d’importance des variables explicatives
Un graphique d’importance des variables explicatives répertorie par ordre décroissant les variables les plus significatives dans la prédiction d’un modèle.
Les variables du haut contribuent plus au modèle que les celles du bas et ont donc un pouvoir prédictif élevé.
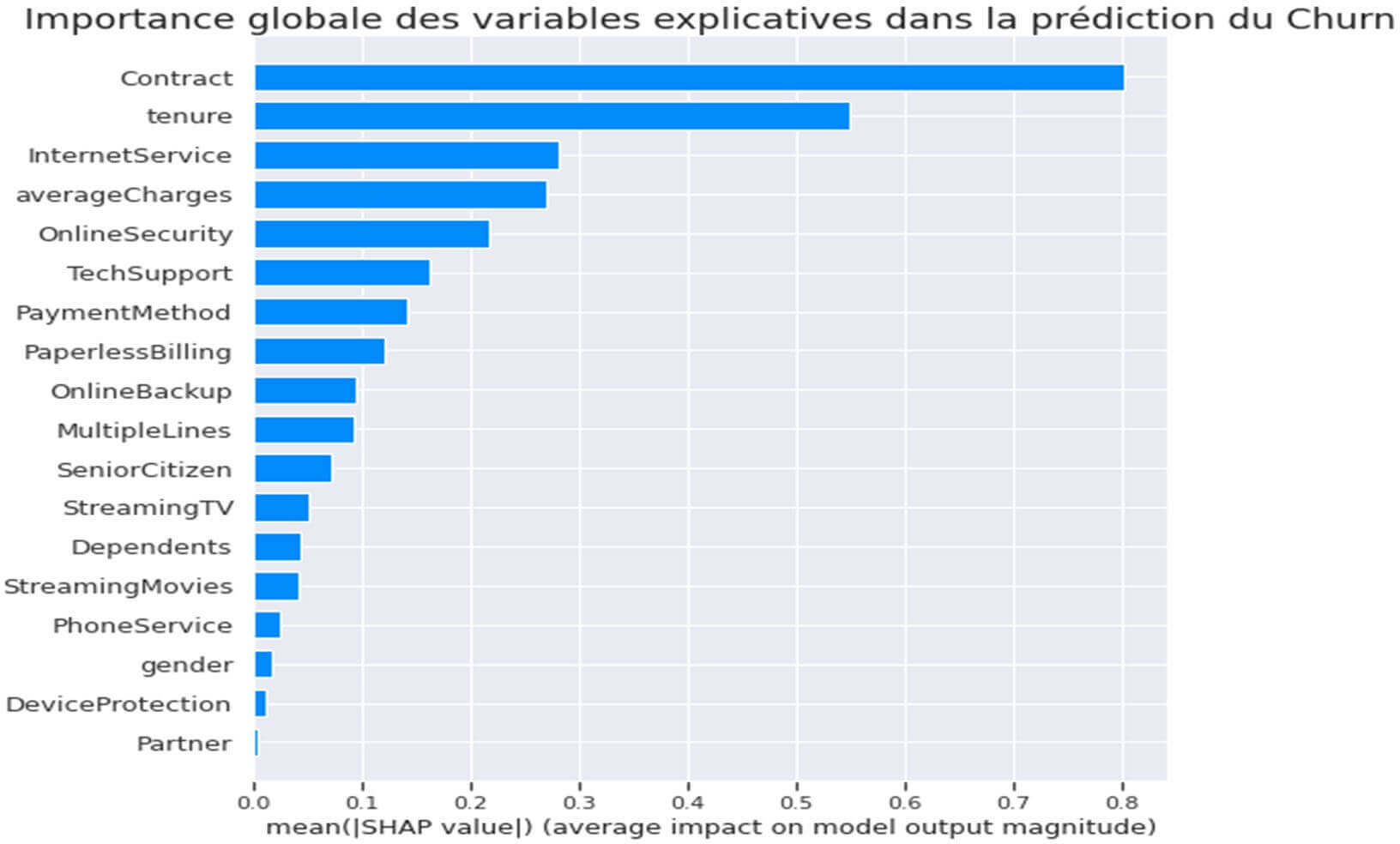
Figure 22: Graphique d’importance des variables explicatives
Ce graphique nous indique que le top 5 des variables explicatives les plus significatives dans la prédiction du Churn client seraient la durée du contrat (Contract), le nombre de mois pendant lequel un client est resté dans la société(tenure), le type de service internet (InternetService), le montant moyen facturé(averagecharges) et la sécurité en ligne (OnlineSecurity).
1.2.4.1.2 Le Summary plot
Le “Summary plot” est un tracé qui va nous permettre de montrer de manière globale les relations positives ou négatives des variables explicatives avec le Churn des clients.
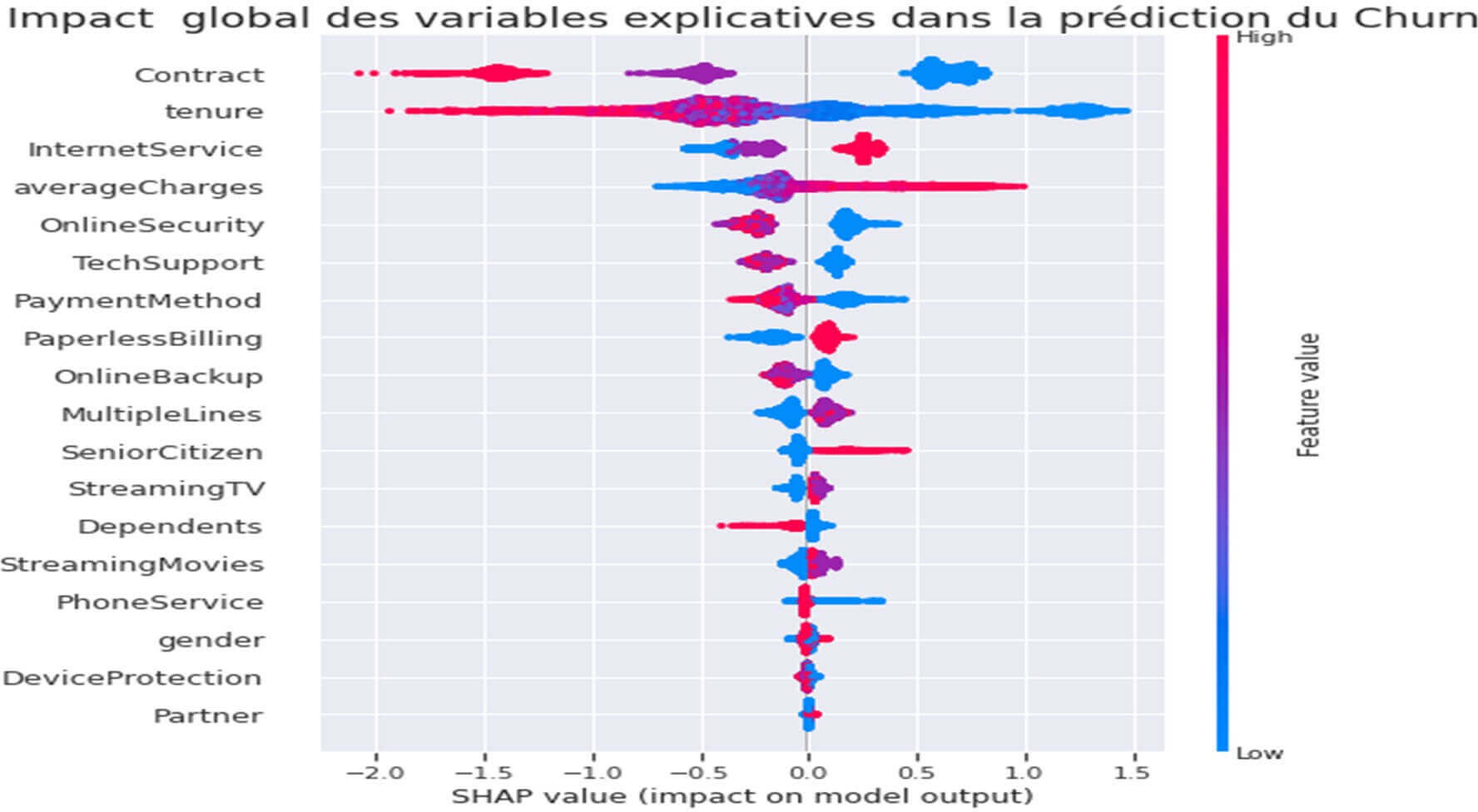
Figure 23 : Summary Plot – Variables explicatives.
Comment comprendre ce tracé ? :
- L’axe des ordonnées reprend les variables explicatives par ordre décroissant d’importance comme pour le précédent tracé.
- L’axe des abscisses représente les valeurs SHAP. Une valeur négative indique une relation négative et une valeur positive indique une relation positive de la variable explicative avec la prédiction du Churn.
- Les points à l’intérieur du tracé représentent l’impact globale positive ou négative de la variable explicative correspondante.
- La barre de couleur sur la droite indique si pour un client donné la valeur de la variable est élevée (couleur rouge) ou basse (couleur bleue).
Le tracé nous indique que globalement il existerait une corrélation négative entre les variables (Contract, tenure, OnlineSecurity, TechSupport, PaymentMethod, OnlineBackup, Dependents, PhoneService) avec la prédiction du Churn du client. En d’autres termes quand la valeur de ces variables augmente, le Churn des clients aurait tendance à baisser.
Par exemple pour la variable « Dépendent » le fait de passer de « No=0 » à « Yes=1 » (Voir tableau d’encodage plus bas) fait baisser le Churn, c’est-à-dire que les clients sans personne à charge seraient plus « fidèles » que ceux avec personne à charge.
Nous retrouvons ici un des points des résultats obtenus plus haut dans le cadre de l’analyse exploratoire de notre jeu de données.
Le tracé nous indique aussi que globalement il existerait une corrélation positive entre les variables (InternetService, averagecharges, PaperlessBilling, MultipleLines, SeniorCitizen, StreamingTV, StreamingMovies) avec la prédiction du Churn du client. En d’autres termes quand la valeur de ces variables augmente, le Churn des clients a tendance aussi à augmenter.
Par exemple pour la variable SeniorCitizen » le fait de passer de 0 à 1 (Voir tableau d’encodage plus haut) fait augmenter le Churn, c’est-à-dire qu’en règle générale les clients jeunes seraient plus fidèles que les clients adultes.
Nous retrouvons ici encore un des points des résultats obtenus plus haut dans le cadre de l’analyse exploratoire de notre jeu de données.
2.4.1.1.3 Le dépendance plot
Le « Dependence Plot » est un tracé qui va nous permettre de montrer de manière globale l’effet marginal d’une ou deux variables explicatives dans la prédiction du Churn.
La fonction qui permet de tracer le « dependence plot » d’une variable inclut automatiquement une autre variable avec laquelle cette variable interagit le plus
Dans ce qui va suivre nous allons tracer le « Dependence plot » pour toutes les seize variables explicatives de notre modèle. Pour la compréhension de nos tracés nous aurons besoin du tableau suivant récapitulant l’encodage des variables qualitatives utilisé dans la conception de notre modèle.
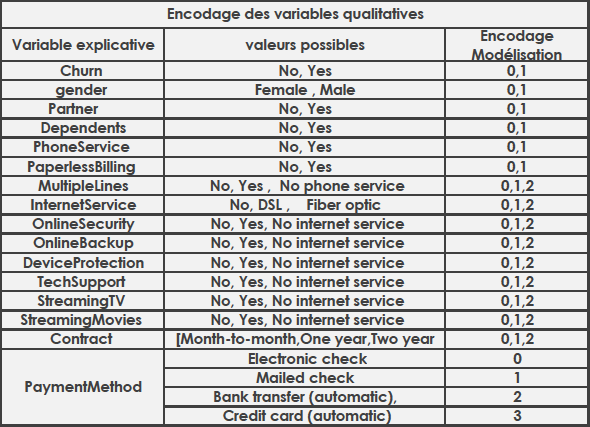
Figure 24: Encodage des variables qualitatives (Source personnelle)
Dependence Plot de la variable « Gender »
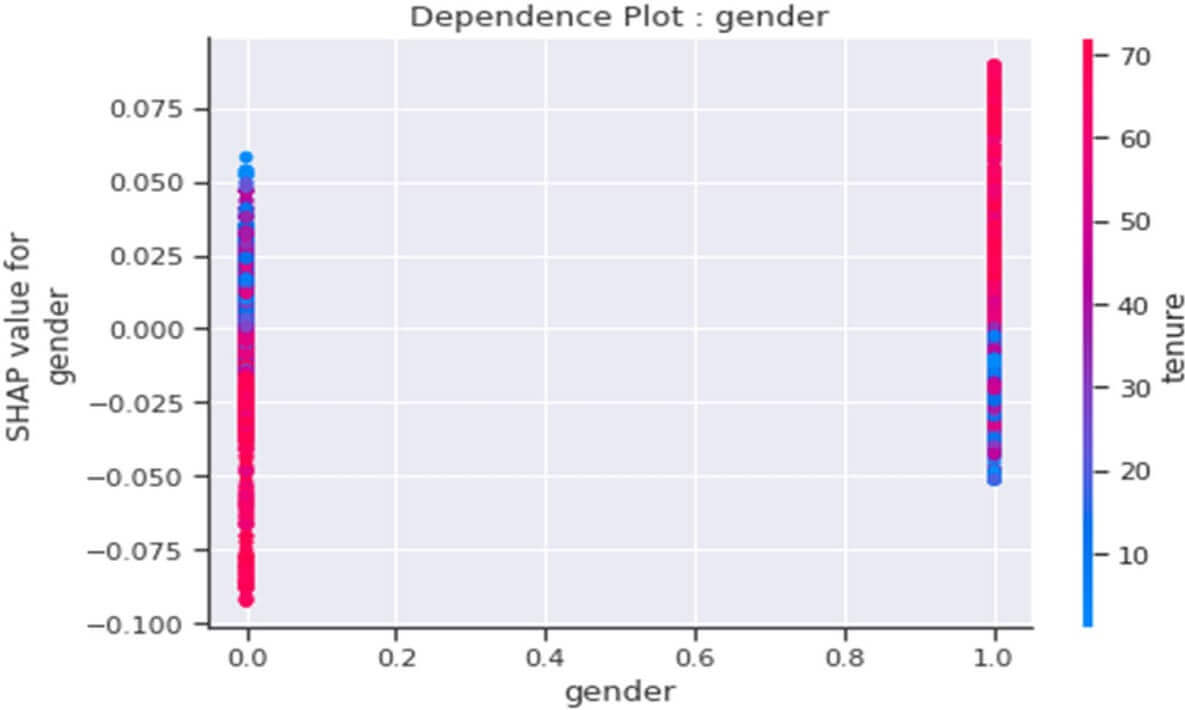
Figure 25 : Dependence Plot de la variable « Gender »
Comment comprendre ce tracé ?
- L’axe des ordonnées représente les valeurs SHAP de la variable choisie, en l’occurrence la variable ‘Gender’.
- L’axe des abscisses représente les valeurs initiales de la variable choisie, en l’occurrence la variable ‘Gender ‘.
- La barre de couleurs sur la droite représente une échelle pour les valeurs initiales de la variable ‘tenure’ passant d’une valeur basse (couleur bleue) à une valeur élevée (couleur rouge). Notre modèle a estimé que la variable ‘tenure ‘ est celle qui serait le plus en interaction avec la variable ‘Gender’.
- Les points à l’intérieur du tracé représentent l’impact global conjugué des deux variables (Tenure et Gender) dans la prédiction du Churn.
Ce tracé nous indique globalement que :
- Pour les femmes (Gender=0), plus leur durée de présence dans la société augmente plus leur Churn baisserait.
- Pour les hommes (Gender=1), plus leur durée de présence dans la société augmente plus leur Churn augmenterait.
Dependence plot de la variable « SeniorCitizen »
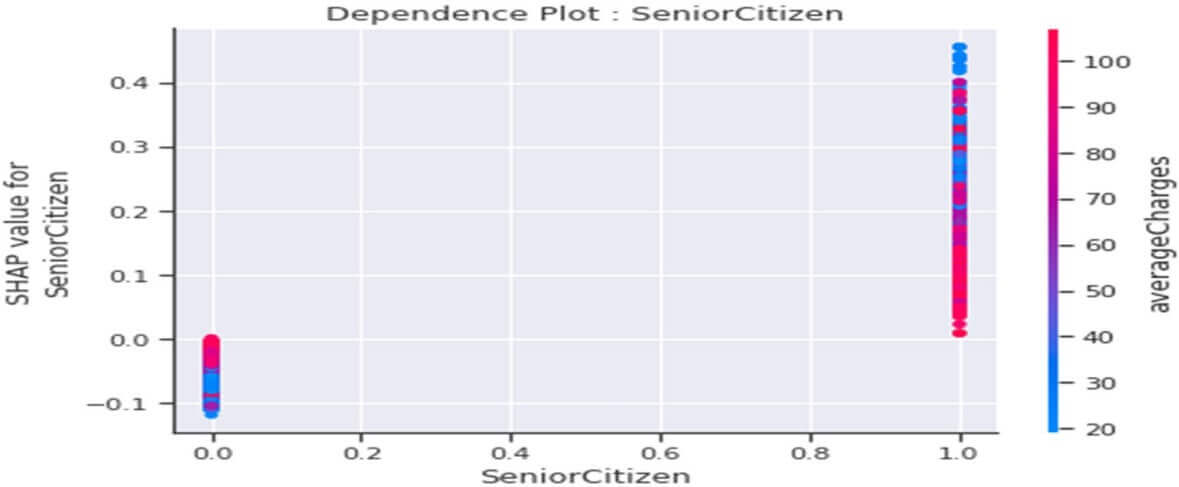
Figure 26: Dependence Plot de la variable « SeniorCitizen »
Ce tracé nous indique que :
- Le client jeune (SeniorCitizen=0) serait plutôt « fidèle » à la société (valeurs SHAP <0) et ce comportement s’accentuerait avec la baisse du montant moyen des charges à payer (‘averagecharges).
- Le client Senior (SeniorCitizen=1) aurait plutôt une propension à « l’infidélité » vis- à-vis de la société (valeurs SHAP >0) et ce comportement se renforcerait avec la diminution du montant moyen des charges à payer, c-à-d que parmi les clients seniors ceux qui paient le plus seraient les plus « fidèles » (résultat quand même bizarre, il doit vraisemblablement avoir une autre raison qui expliquerait cela).
Dependence plot de la variable « Partner »
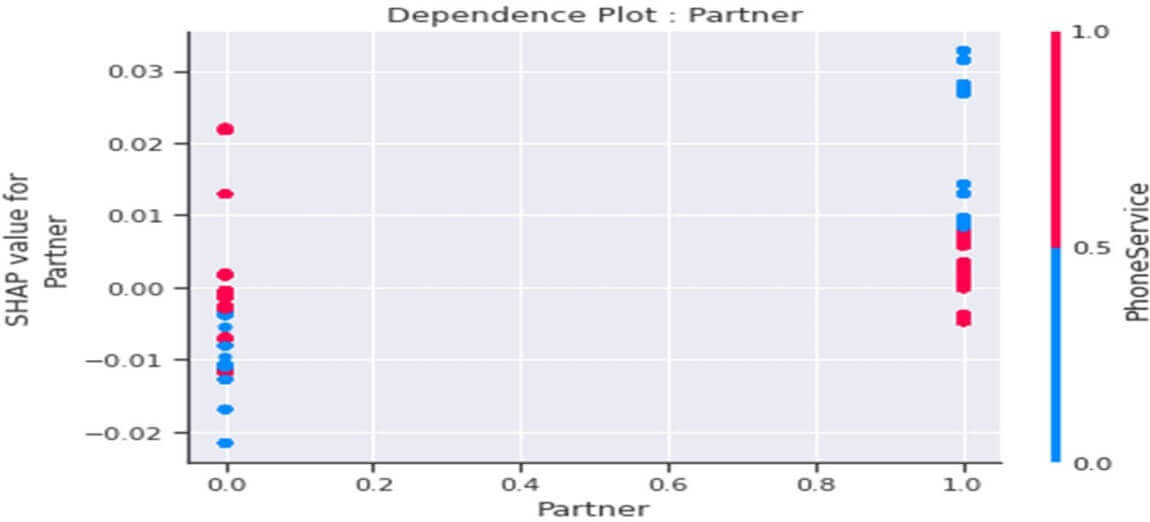
Figure 27 : Dependence Plot de la variable « Partner »
Le tracé ci-dessus nous indique que :
- Globalement un client sans partenaire (Partner=0) serait plutôt « fidèle » à la société (valeurs SHAP<0) et le fait de ne point disposer d’un service de téléphonie (PhoneService =0) renforcerait ce comportement.
- Globalement le client avec partenaire (Partner=1) serait plutôt pas « fidèle » à la société (valeurs SHAP>0) et le fait en plus qu’il n’ait pas de « PhoneService » augmenterait ce comportement.
Dependence plot de la variable « Dependents »
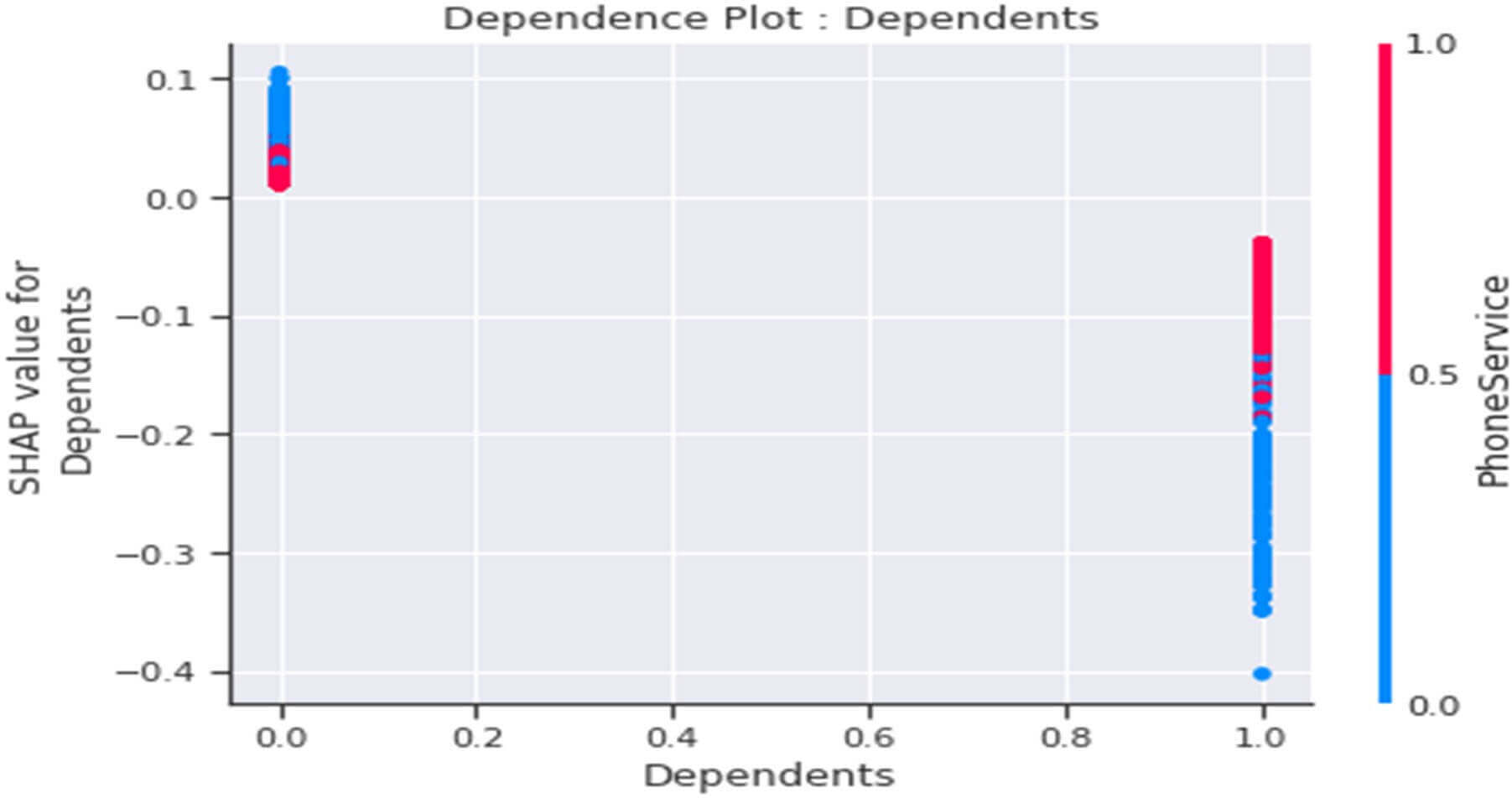
Figure 28 : Dependence Plot de la variable « Dependents »
Ce tracé nous indique que :
- Globalement les clients sans personne à charge (Dependents=0) auraient plutôt une propension au Churn (valeurs SHAP positives) et le fait en plus qu’ils aient aucun service de téléphonie (PhoneService=0) renforcerait ce comportement.
- Globalement les clients avec personne à charge (Dependents=1) auraient plutôt une propension à la fidélité (valeurs SHAP comprises entre -0.4 et 0) et le fait en plus qu’ils ne disposent pas de service de téléphonie (PhoneService =0) renforcerait ce comportement.
Dependence plot de la variable « Tenure »
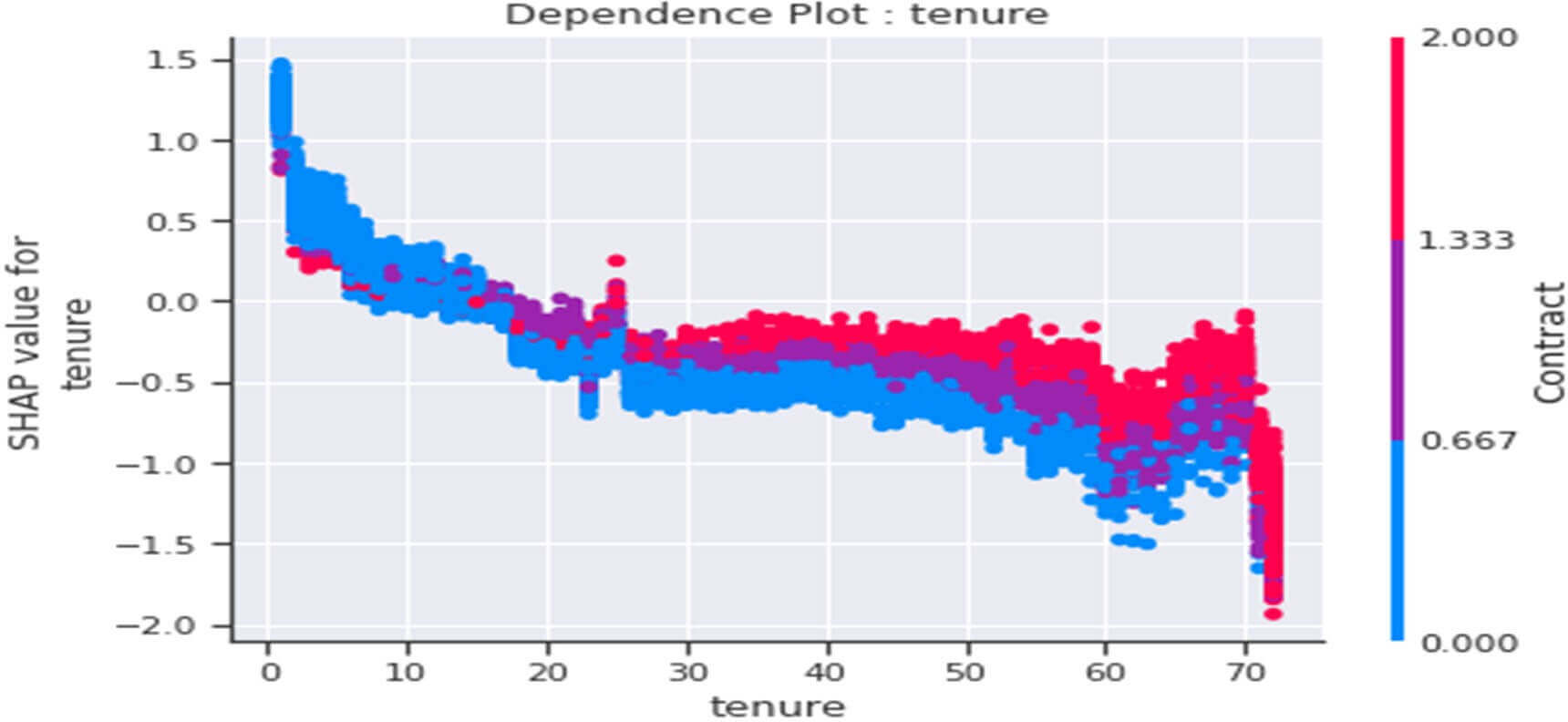
Figure 29 : Dependence Plot De la variable « tenure »
Ce tracé nous indique ceci :
- D’une manière générale, les clients qui passent moins de 10 mois dans la société(tenure<=10) seraient plutôt « infidèles » (valeurs SHAP >0).
- A partir de 10 mois de présence dans la société, les clients seraient plutôt « fidèles » (valeurs SHAP<0) et ce comportement se renforcerait à partir de 20 mois de présence dans société pour les clients ayant une durée de contrat initial élevée (Contract=2 équivaut à un contrat de deux ans).
Dependence plot de la variable « MultipleLines »
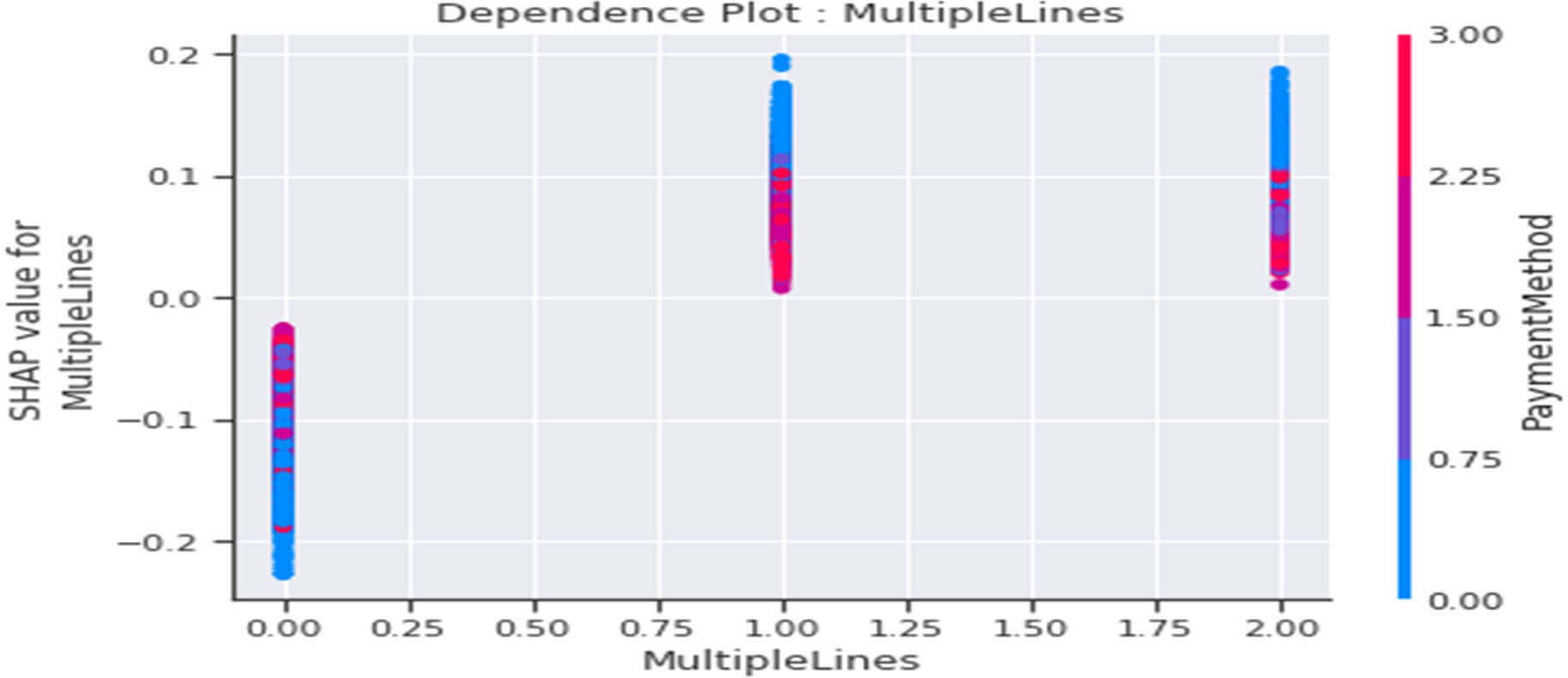
Figure 30 : Dependence Plot de la variable « MultipleLines »
Le tracé ci – dessus nous indique que :
- Globalement les clients ne disposant pas du tout de service de téléphonie (MultipleLines=2 qui correspond à ‘no phone’) auraient plutôt une propension au Churn et le fait en plus qu’ils paient en chèque « « electronic check » (PaymentMethod=0) augmenterait ce comportement. Ce comportement serait le même pour les clients disposant d’un service de téléphonie avec une option multilignes (MultipleLines=1).
- Globalement les clients disposant d’un service de téléphonie sans option MultiplesLines (MultipleLines=0) auraient une propension à la fidélité (Valeurs SHAP<0) et ce comportement augmenterait avec le fait qu’ils payent en « electronic check ».
Dependence plot de la variable « Internet Service »
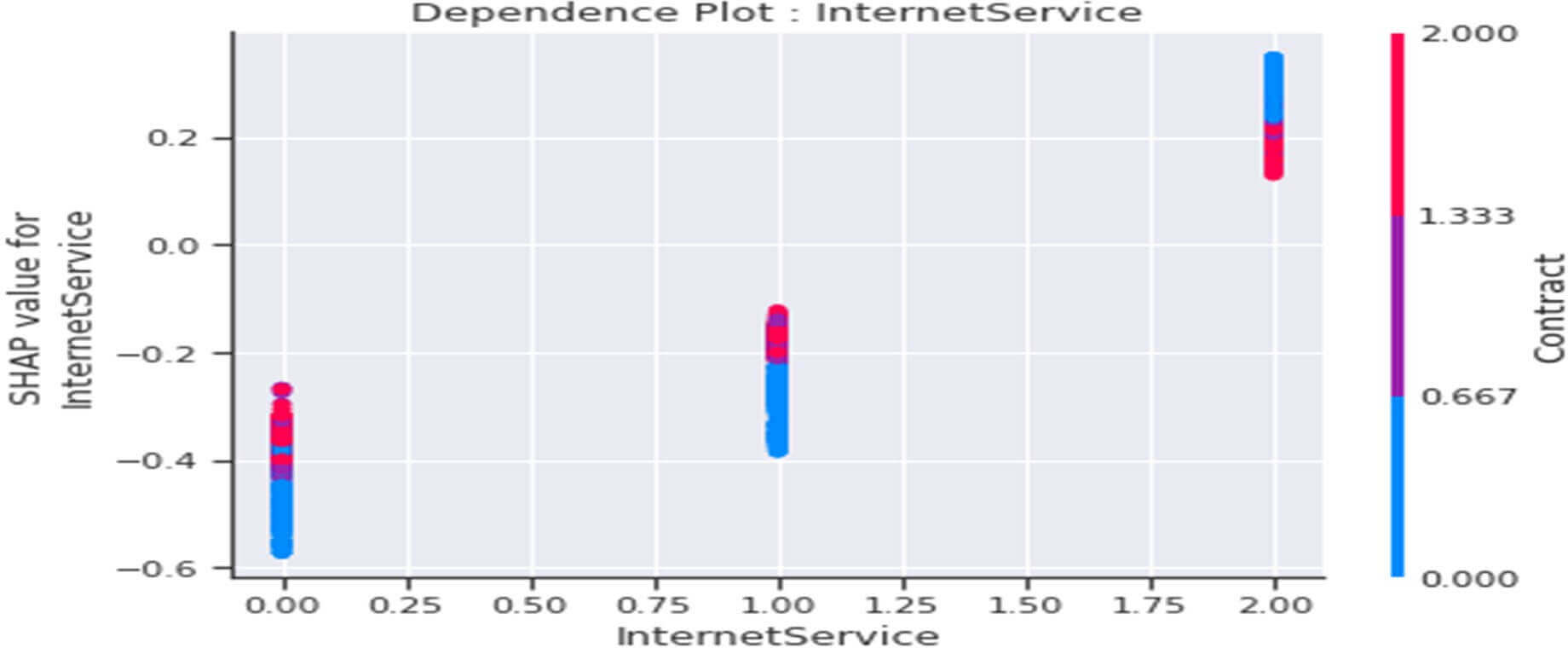
Figure 31 : Dependence Plot de la variable « InternetService »
Ce tracé nous indique ceci :
- D’une manière générale, les clients n’ayant pas souscrit de service internet (Internet Service=0) seraient plutôt « fidèles » à la société et ce comportement augmenterait avec le fait qu’ils aient en plus un contrat de type « month -to month » (Contract=0).
- Ce comportement serait similaire aux clients ayant souscrit un service internet de type ADSL (Internet Service=1).
- Les clients ayant souscrit un service internet de type « Fiber optic » (Internet Service=2) seraient plutôt non « fidèles » à la société et ce comportement serait accentué parmi les clients ayant souscrit en même temps un contrat de type « « month-to- month ».
Dependence plot de la variable « OnlineSecurity »
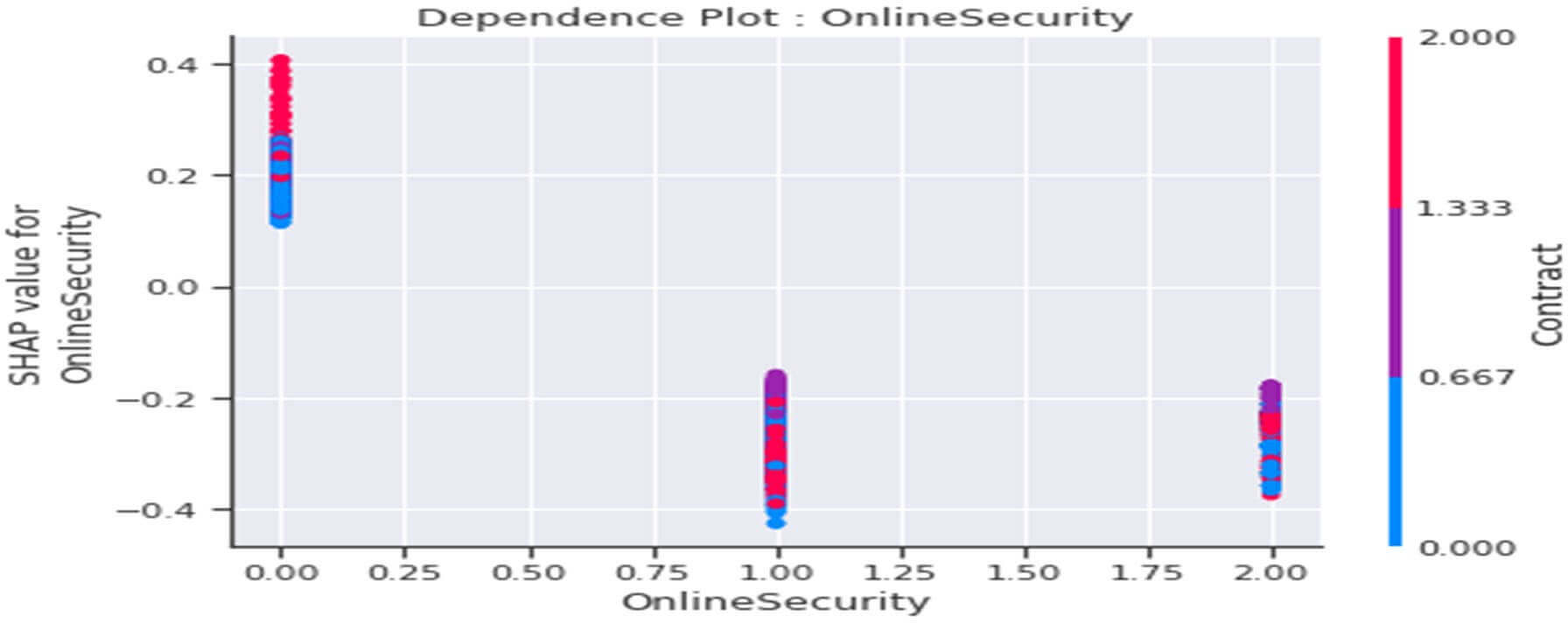
Figure 32 : Dependence Plot de la variable « OnlineSecurity »
Ce tracé nous indique ceci :
- Globalement, les clients ayant souscrit à un service internet sans l’option sécurité Online (OnlineSecurity=0) auraient une propension à « l’infidélité » vis -à-vis de la société (valeurs SHAP>0) et ce comportement serait accentué parmi les clients avec en plus un contrat de base de type « Two year » (Contract =2).
- Globalement les clients ayant souscrit à un service internet avec option sécurité online (OnlineSecurity=1) seraient plutôt « fidèles » (Valeurs SHAP<0) et ce indépendamment du type de contrat.
Dependence plot de la variable « OnlineBackup »
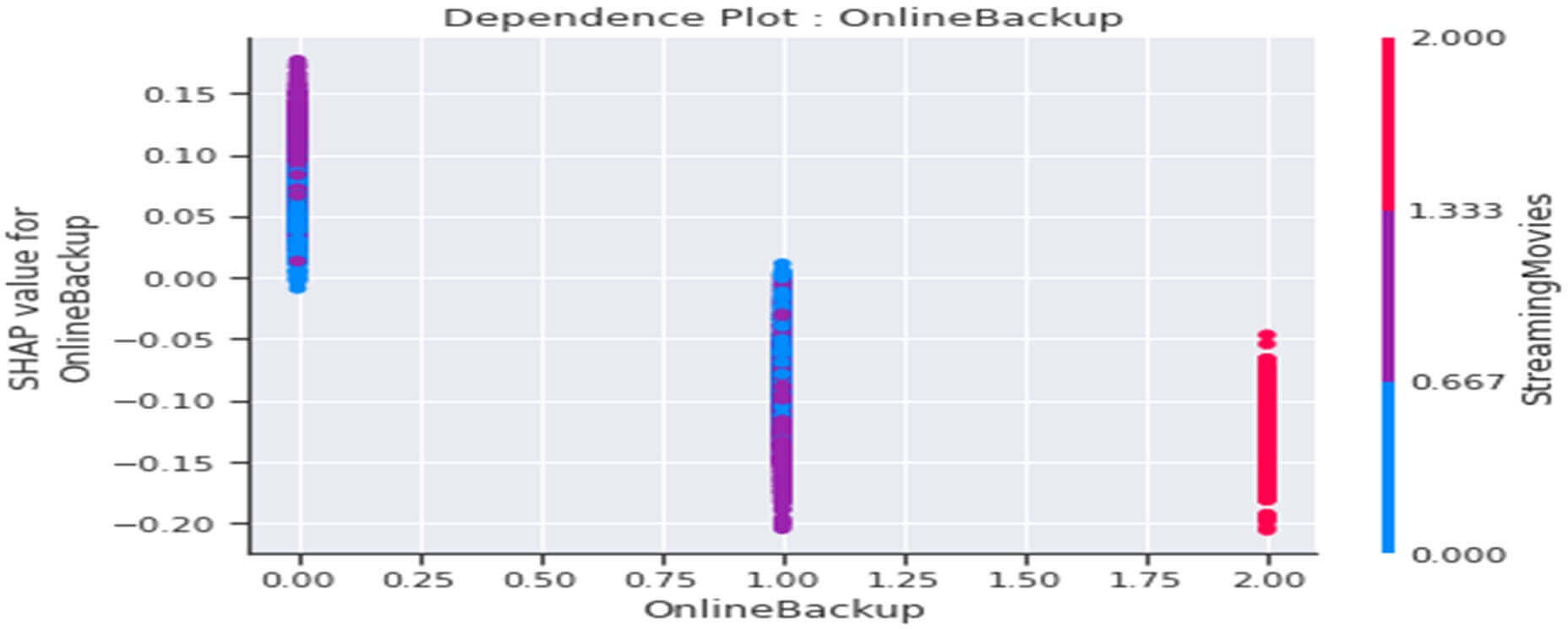
Figure 33 : Dependence Plot de la variable « OnlineBackup »
Ce tracé nous indique que :
- Globalement les clients n’ayant pas souscrit d’option onlineBackup dans leur abonnement d’internet (OnlineBackup=0) seraient plutôt « infidèles » et ce comportement serait accentué parmi les clients disposant en plus d’un service de StreamingMovies (StreamingMovies=1).
- Globalement les clients ayant souscrit une option onlineBackup dans leur abonnement d’internet (OnlineBackup=1) seraient plutôt « fidèles » (‘valeurs (SHAP<0) et ce comportement serait accentué parmi les clients disposant en plus d’un service de StreamingMovies (StreamingMovies=1).
- D’une manière générale, les clients n’ayant point souscrit d’abonnement internet (OneBackup=2 et StreamingMovies=2) seraient plutôt « fidèles » à la société.
Dependence plot de la variable « DeviceProtection »
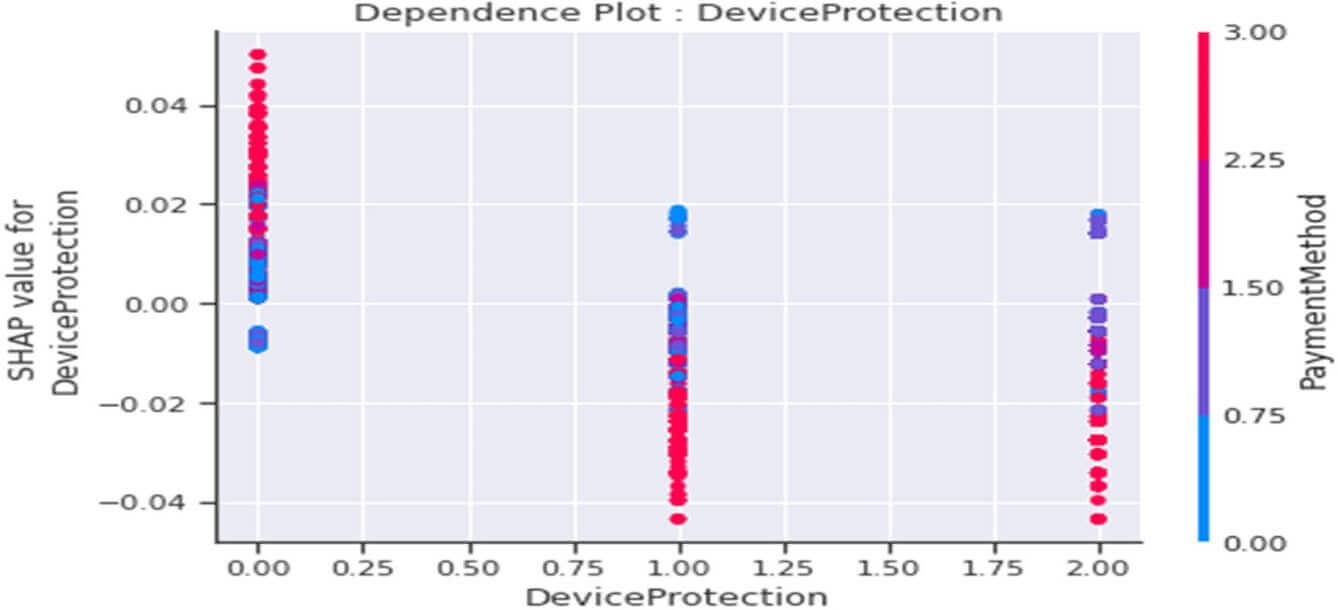
Figure 34 : Dependence Plot de la variable « DeviceProtection »
Ce tracé nous indique ceci :
- Globalement les clients n’ayant pas souscrit d’option « DeviceProtection » dans leur abonnement internet seraient plutôt « infidèles » (valeurs SHAP>0) et ce comportement serait accentué parmi les clients qui paient en « Bank Transfer (automatic) =2 » ou « ‘Credit card (automatic) =3 ».
- Globalement les clients ayant souscrit une option « DeviceProtection » dans leur abonnement internet seraient plutôt « fidèles » (valeurs SHAP<0) et ce comportement serait renforcé parmi les clients qui paient en plus en « Bank Transfer (automatic) » ou « ‘Credit card (automatic)’ ». Ce comportement serait le même pour les clients ne disposant pas du tout d’un abonnement internet.
Dependence Plot de la variable « TechSupport »
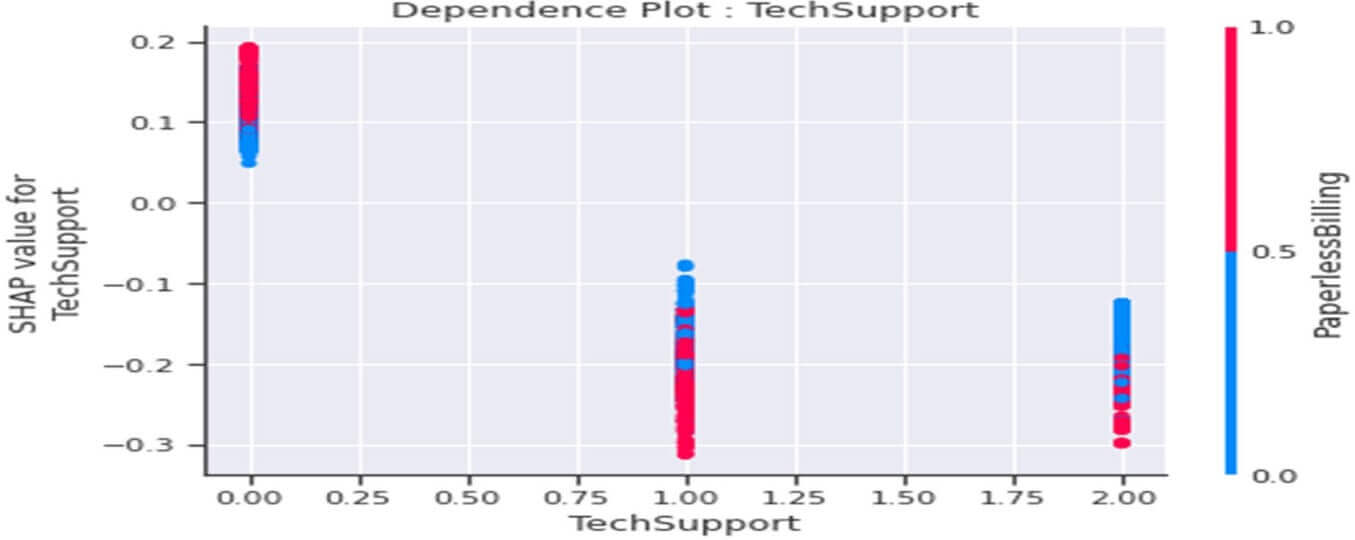
Figure 35 : Dependence Plot de la variable « TechSupport »
Ce tracé nous indique que :
- Globalement les clients n’ayant pas souscrit l’option « TechSupport » dans leur abonnement internet (TechSupport=0) seraient plutôt « infidèles » (valeurs SHAP>0 et ce comportement serait accentué parmi les clients qui même temps ont opté pour un « PaperlessBilling » (PaperlessBilling=1).
- Globalement les clients ayant souscrit l’option « TechSupport » dans leur abonnement internet (TechSupport=1) seraient plutôt fidèles (valeurs SHAP<0) et ce comportement serait renforcé parmi les clients qui en même temps auraient opté pour le « PaperlessBilling » (PaperlessBilling=1). Ce comportement serait le même pour les clients n’ayant pas du temps souscrit à un abonnement internet. (TechSupport=2).
Dependence plot de la variable « StreamingTV »
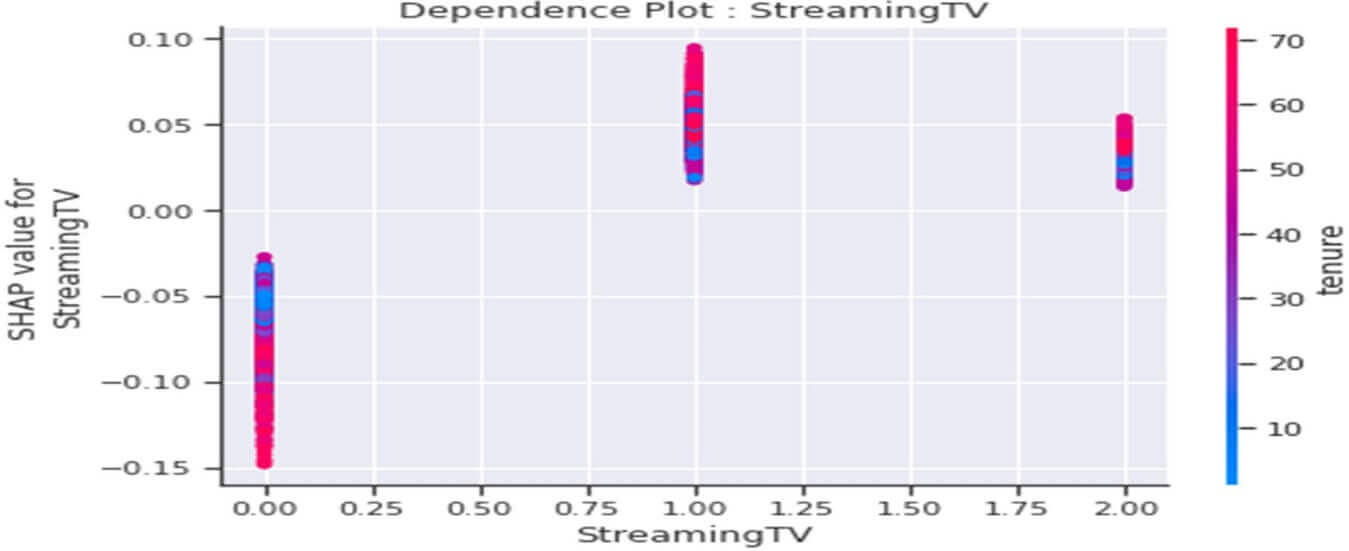
Figure 36 : Dependence Plot de la variable « StreamingTV »
Ce tracé ci-dessus nous indique que :
- En général les clients ne disposant pas d’option StreamingTV (StreamingTV=0) dans leur abonnement internet seraient plutôt « fidèles » (valeurs SHAP <0) et ce sentiment augmenterait avec l’augmentation de la durée de présence dans la société.
- En général les clients ayant souscrit l’option « StreamingTV » dans leur abonnement internet (StreamingTV=1) seraient plutôt « infidèles » (valeurs SHAP>0) et ce comportement se renforcerait avec l’augmentation de la durée de présence dans la société. Ce comportement serait le même pour les clients ne disposant pas du tout de service internet (StreamingTV=2).
Dependence plot de la variable « Contract »
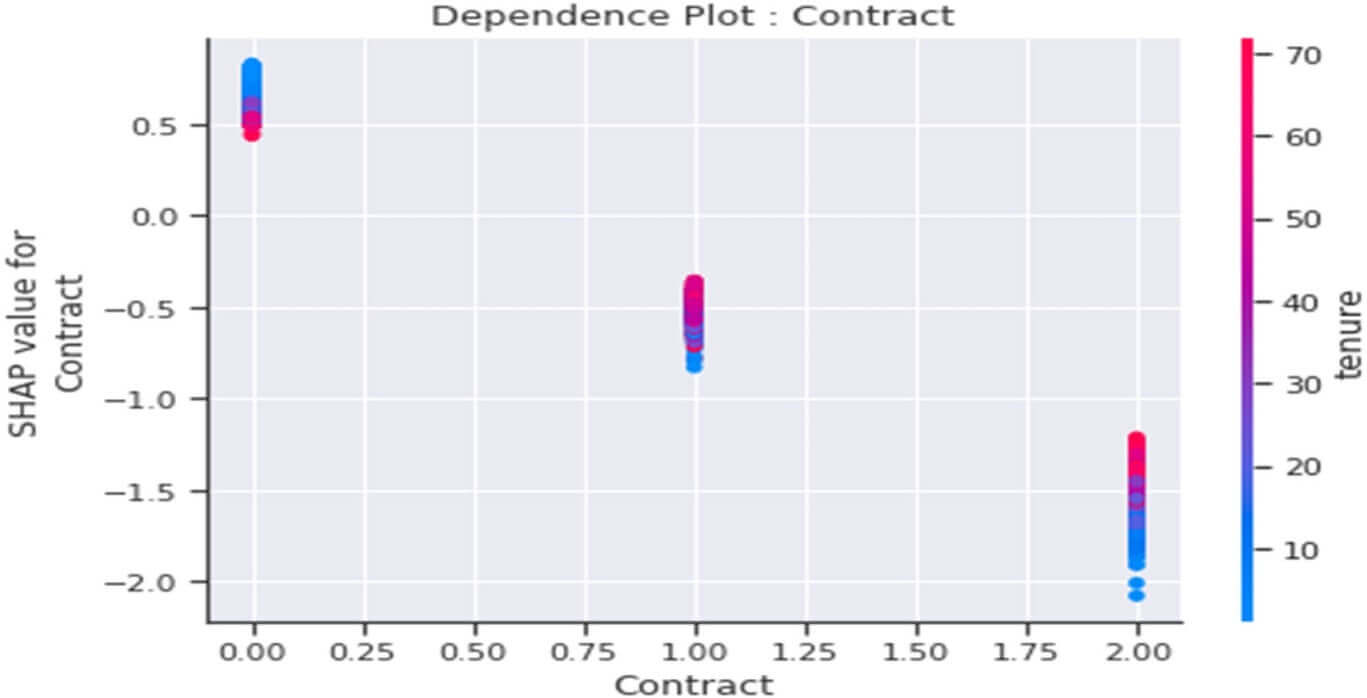
Figure 37 : Dependence Plot de la variable « Contract »
Ce tracé nous indique que :
- En général les clients ayant souscrit un contrat de base de type « month-to-month » (Contract=0) seraient plutôt « infidèles » (valeurs SHAP>0) et ce comportement serait accentué parmi les clients ayant en plus qu’une petite durée de présence dans la société.
- En général les clients ayant souscrit un contrat de base de type « one year » ou « Two years » (Contract=1 ou 2) seraient plutôt « fidèles » à la société (valeurs SHAP<0) et ce comportement serait accentué parmi les clients ayant en plus qu’une petite durée de présence dans la société.
Dependence plot de la variable « PaperlessBilling »
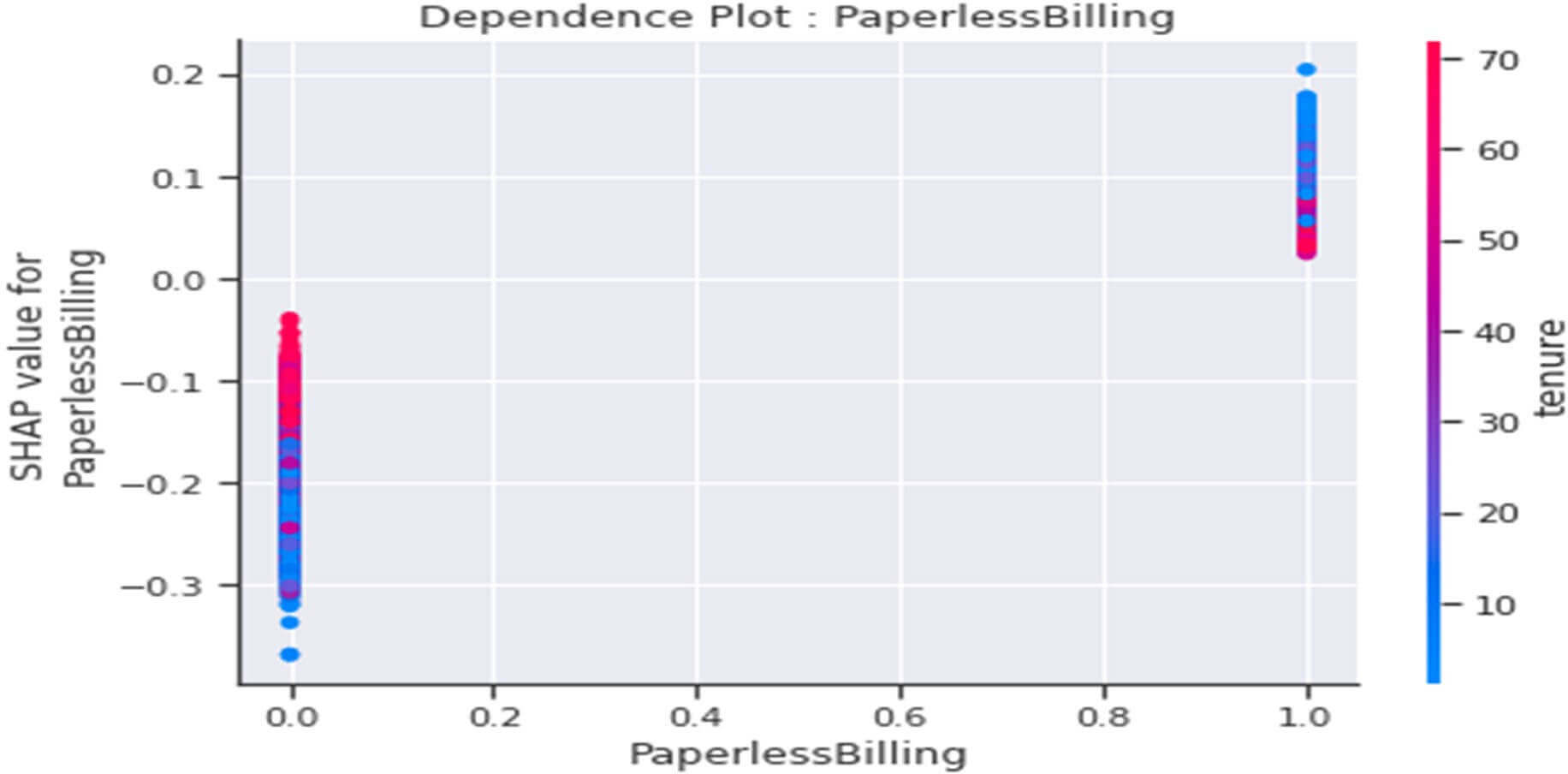
Figure 38 : Dependence Plot de la variable « PaperlessBilling »
Ce tracé nous indique que :
- En général les clients ne disposant pas d’un « PaperlessBilling =0 » seraient plutôt « fidèles » (valeurs SHAP<0) et ce comportement serait accentué parmi les clients ayant en plus qu’une petite durée de présence dans la société.
- En général les clients disposant d’un « PaperlessBilling =1 » seraient plutôt « infidèles » (valeurs SHAP>0) et ce comportement serait accentué parmi les clients ayant en plus qu’une petite durée de présence dans la société.
Dependence plot de la variable PaymentMethod
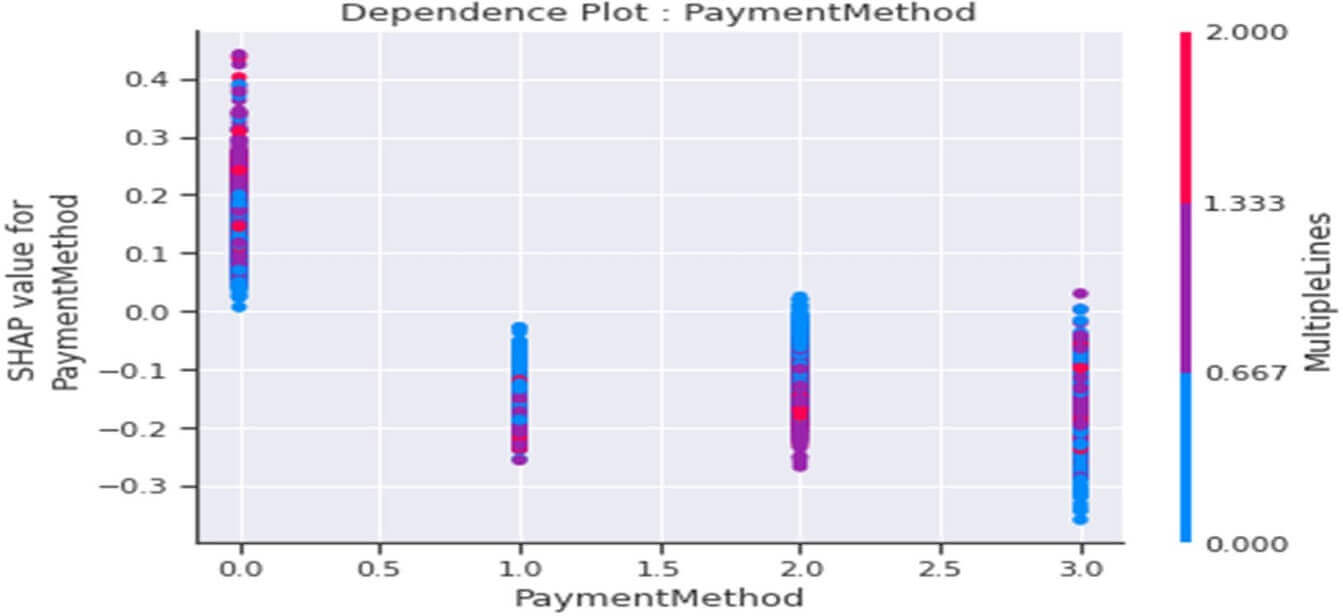
Figure 39: Dependence Plot de la variable « PaymentMethod »
Ce tracé nous indique que d’une manière générale :
- Les clients ayant opté pour le mode de paiement de type « Electronic check » (PaymentMethod=0) seraient plutôt « infidèles » (valeurs SHAP>0).
- Les clients ayant opté pour les modes de paiement de type « Mailed check » ou « Bank Transfer (automatic) » (PaymentMethod=1 ou 2) seraient plutôt « fidèles » (valeurs SHAP<0) avec un comportement de fidélité accentué parmi les clients ayant souscrit à l’option « MultipleLines » (MultipleLines =1).
- Les clients ayant opté pour les modes de paiement de type « Credit card (automatic) » (PaymentMethod=3) seraient plutôt « fidèles » (valeurs SHAP<0) avec un comportement de fidélité accentué parmi les clients n’ayant pas souscrit l’option « MultipleLines » (MultipleLines=0)
Dependence plot de la variable averagecharges
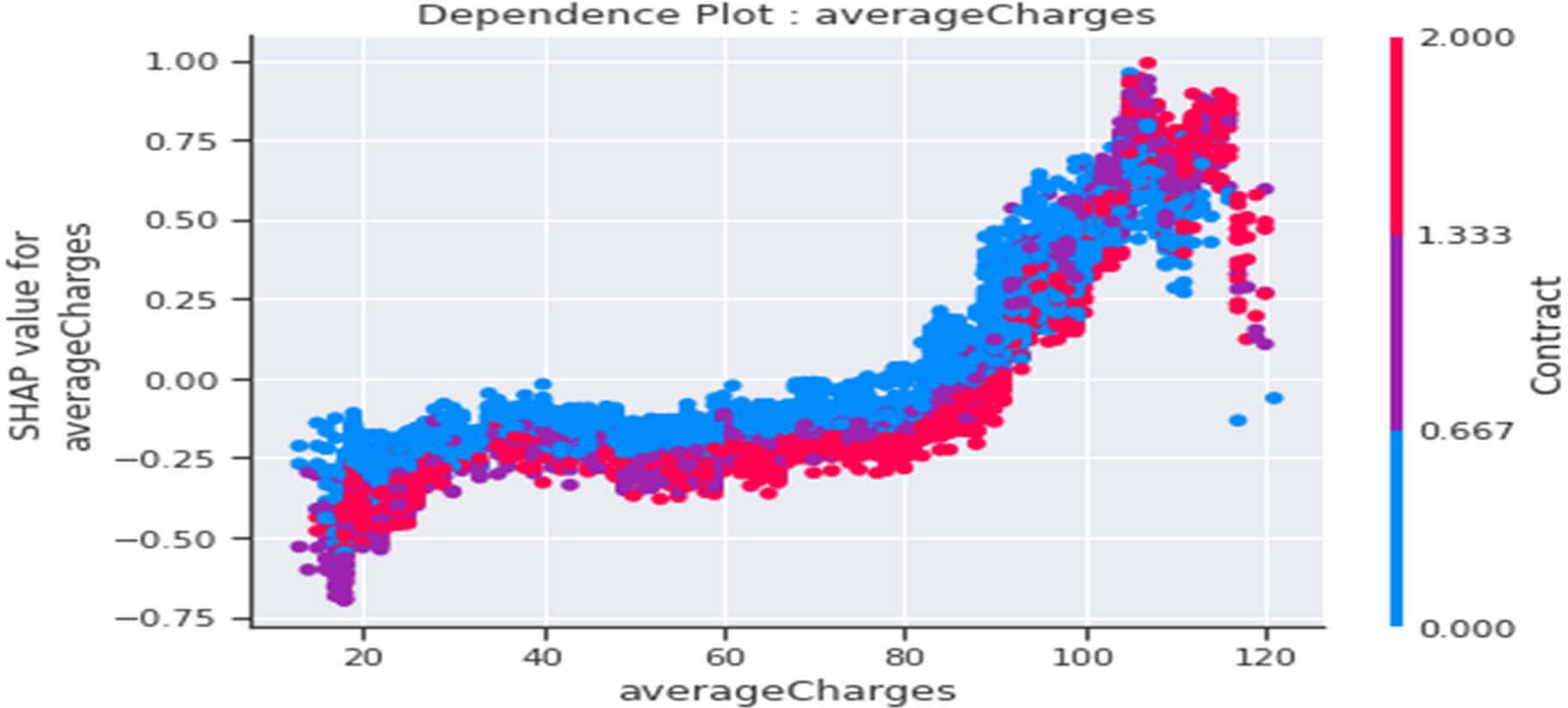
Figure 40 : Dependence Plot de la variable « Averagecharges »
Ce tracé nous indique que globalement :
- Jusqu’à un montant environ de 90$ de « averagecharges » les clients seraient plutôt « fidèles » (valeurs SHAP<0) et ce comportement serait accentué parmi les clients ayant en plus un petit contrat de base de type « month-to-month » (couleur bleue).
- Entre 90 et 110 $ de « averagecharges » les clients seraient plutôt « infidèles » (valeurs SHAP>0) et ce comportement serait accentué parmi les clients ayant en plus un petit contrat de type « month-to-month » (couleur bleue).
- A partir de 110$ de « averagecharges » les clients seraient plutôt « infidèles » (valeurs SHAP>0) et ce comportement serait accentué parmi les clients ayant en plus un grand contrat de base de type « Two years » (couleur rouge).
1.2.4.2 Explicabilité du modèle
Dans ce qui va suivre nous allons continuer à utiliser les valeurs SHAP pour analyser l’impact des variables explicatives sur la prédiction du Churn de manière locale c’est-à-dire individuellement pour chaque client.
A ce titre nous allons utiliser le tracé connu en anglais sous la désignation de « Individual force plot ». En théorie, ce tracé peut être obtenu pour tous les 7043 lignes (clients) que contient notre jeu de données mais pour étayer notre démarche ,nous allons nous limiter à 3 clients pris au hasard.
Pour l’explication des tracés à venir nous aurons besoin du graphique suivant sur la régression logistique :
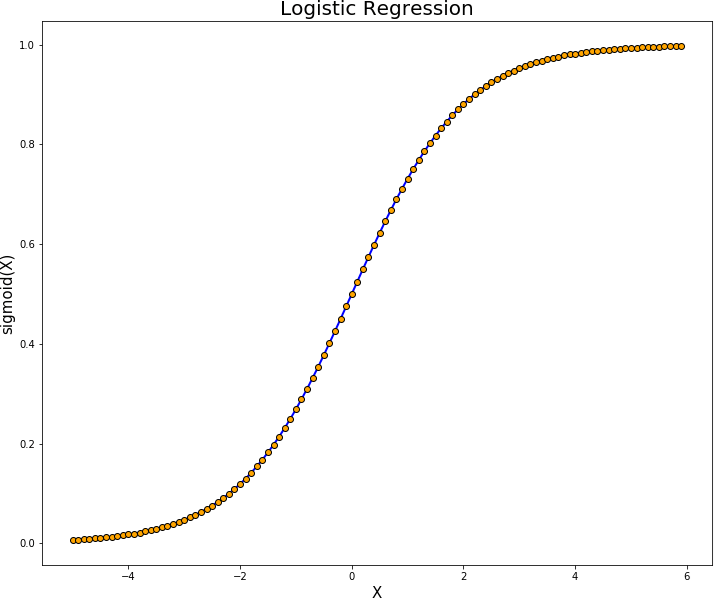
Figure 41: Logistic Regression (Source : http://towardsdatascience.com/logistic‐regression‐explained‐9ee73cede081)
Individual Force Plot du client N° 6650
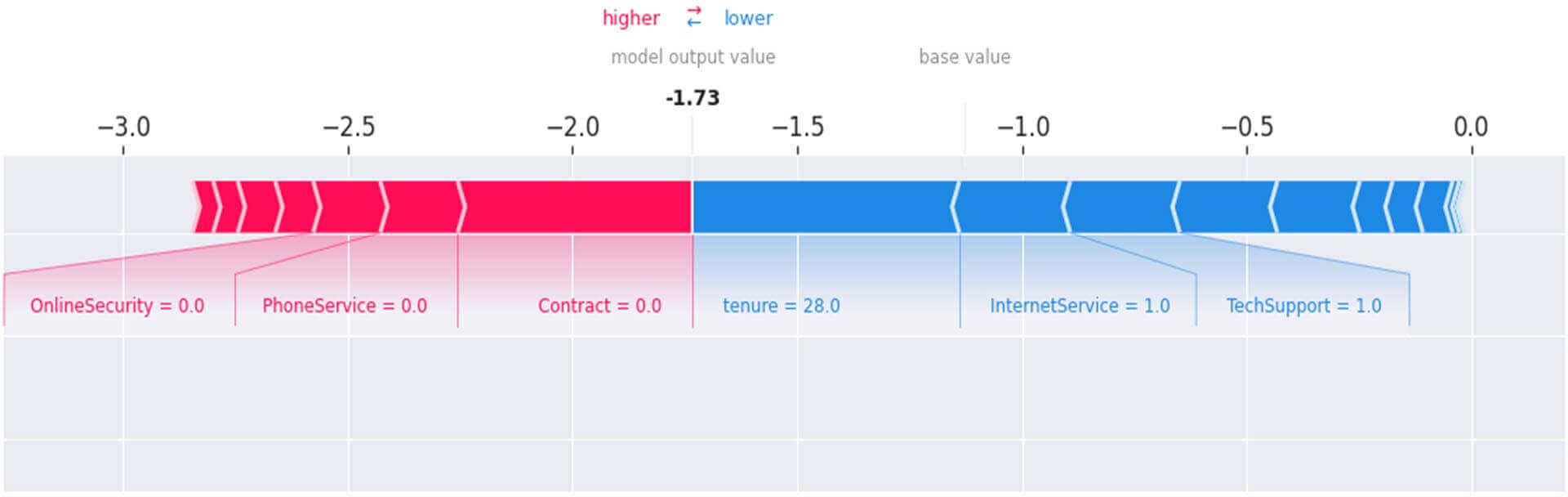
Figure 42 : Individual Force Plot du client N° 6650
Comment comprendre ce tracé ?
- Les valeurs sur l’axe sont les valeurs SHAP représentées sous forme de probabilité en termes de régression logistique (figure citée plus haut).
- La valeur base value= -1 est la prédiction moyenne du taux du Churn dans notre jeu de données par notre modèle XGBoost.
- La valeur output value = -1.73 est la prédiction du Churn par notre modèle pour le client N°6650.
- La couleur rouge représente les variables explicatives poussant vers le haut la prédiction du Churn du client N° 6650.
- La couleur Bleue représente les variables explicatives poussant vers le bas la prédiction du Churn du client N° 6650.
En résumé le tracé nous indique que :
- Le taux d’attrition moyen que pourrait prédire notre modèle XGBoost pour notre jeu de données est d’un peu plus de 25% qui est la correspondance de la valeur -1 de la « base value » dans le graphique susmentionné de la régression logistique. Nous voyons bien que ce taux n’est pas loin du celui de 27% obtenu à la suite de l’analyse exploratoire de notre jeu de données.
- Le taux d’attrition prédit par notre modèle pour le client N°6650 se situe aux environs de 10% (correspondance de la outputvalue = -1.73 sur le graphique de régression logistique) .Ce taux signifie qu’il n’y aurait que 10% de chances ou malchances que le client N°6650 quitte la société et cela serait dû essentiellement au fait que ce client a une durée de présence dans la société de 28 mois(tenure=28), a souscrit un service internet (InternetService=1) avec une option de support technique(TechSupport=1).
Individual force plot du client N° 200
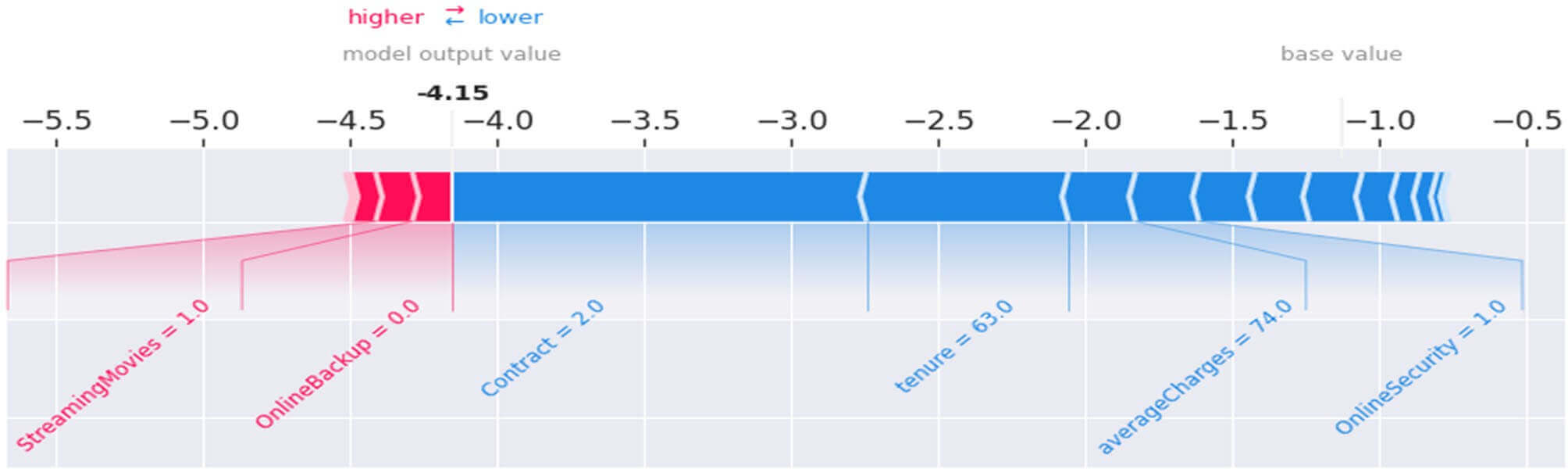
Figure 43 : Individual Force Plot du client N° 200
Ce tracé nous indique que pour le client N°1686 :
- Le taux d’attrition serait aux alentours de 0% (outvalue=-4.15). Ce client serait plutôt « fidèle » à la société et son comportement serait dû essentiellement au fait qu’il ait signé un contrat de type « Two year » (Contract=2), qu’il soit présent dans la société depuis 63 mois (tenure=63.0), qu’il dépense en moyenne 74$ (averagecharges=74) et qu’il ait souscrit une option OnlineSécurity (OnlineSecurity=1) sur son service internet.
Individual Force Plot du client N° 20
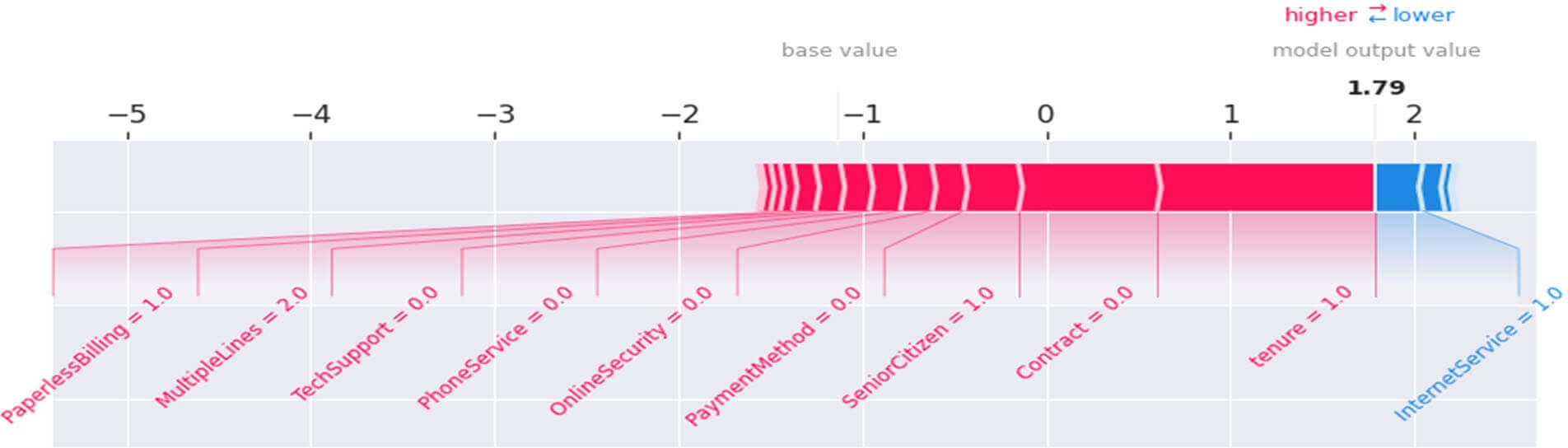
Figure 44 : Individual Force Plot du client N° 20
Ce tracé nous indique que pour le client N°20 :
- Le taux d’attrition ne serait pas loin de 60% (outvalue= 1.79). Ce client serait « infidèle» et son comportement serait dû essentiellement au fait qu’il soit présent dans la société depuis un mois (tenure=1), qu’il ait signé un contrat de type « month- to-month » (Contract=0), qu’il soit une personne âgée (SeniorCitizen=1) et qu’il ait opté pour un mode de paiement de type « Electronic check » (PaymentMethod=0).
Section 2 Analyse des données
A ce stade de notre étude nous allons dans un premier temps, à partir des résultats obtenus dans la section précédente, répondre aux questions de recherche énumérées dans l’introduction générale et ensuite nous allons mettre en perspective nos réponses avec les études déjà existantes sur l’analyse de la fidélité client.
2.1 Résultats obtenus
Comment Prédire le comportement des clients actuels ou futurs relatifs à leur fidélité vis-à-vis d’une société B2C ?
Nous avons vu dans le cas de notre société de télécommunications qu’un algorithme d’apprentissage automatique sur la prédiction de son taux d’attrition pourrait permettre cela.
En l’occurrence les résultats obtenus avec le modèle XGBoost nous a indiqué que dans la vie réelle nous pourrions prédire avec précision dans 81% de cas le comportement futur d’un client actuel ou client futur au regard de son attrition vis-à-vis de la société.
Comment identifier les raisons qui expliqueraient la fidélité ou non des clients d’une société B2C ?
Les résultats de l’analyse exploratoire de notre jeu des données et de l’interprétation de notre modèle XGBoost synthétisés dans les 2 tableaux suivants sont autant des raisons qui pourraient expliquer les comportements de la fidélité relative à l’attrition des clients de cette société des télécommunications.
TABLEAU A COMPLETER
Pouvons-nous élaborer des politiques de fidélisation client grâce à l’apprentissage automatique ?
Les insights, les comportements des clients découverts grâce aux résultats de l’analyse exploratoire et de l’interprétation du modèle nous ont permis de dégager des pistes des réflexions qui sont répertoriées dans les tableaux cités plus haut.
Ces pistes de réflexion pourraient être autant de leviers d’amélioration de la fidélité relative à l’attrition des clients. Au demeurant, nous pensons que ces pistes de réflexion à elles seules ne suffiraient pas à construire des véritables programmes de fidélisation client.
Effet les résultats obtenus à eux -seuls ne suffiraient pas pour déceler les véritables racines de la fidélité ou non des clients parce que tout simplement ils ne sont basés que sur une interprétation et que par définition une interprétation n’identifie que de la corrélation et non la causalité.
En théorie si nous disposons des données pertinentes et bien entendu RGPD compliantes sur les autres KPI de mesure de la fidélité vus plus haut, nous pourrions dérouler notre démarche.
2.2- DISCUSSION
Dans la présente étude nous avons étayé une démarche basée en deux temps principaux
Dans premier temps nous avons montré à travers l’analyse exploratoire des données que notre démarche de l’analyse de la fidélité des clients de la société des télécommunications pourrait permettre de mettre en évidence des insights, certains comportements des clients partis ou restés dans la société qui pourraient expliquer leur fidélité ou non vis-à-vis de la société.
Cette étape en soi n’est pas révolutionnaire car un bon logiciel de CRM pourrait permettre cela.
Dans un deuxième temps nous avons montré que notre démarche pourrait permettre la prédiction de la fidélité client et d’expliquer leur comportement au regard du Churn.
Là encore des nombreuses sociétés ou plateformes internet sont spécialisées en cela.
Néanmoins nous pensons que notre démarche aurait l’avantage de la granularité de l’analyse. En effet, notre revue de littérature sur l’analyse du Churn ne nous a donné que des solutions basées sur une approche globale de l’analyse là où notre démarche arriverait à expliquer le Churn de manière locale, à l’individu.
De surcroit les études existantes sur le marché en tout cas celles sur lesquelles nous sommes tombés dans notre phase de revue de littérature ne traiteraient la fidélisation client que sous le prisme du Churn. A ce titre nous pensons que la valeur ajoutée de notre démarche de l’analyse de la fidélité client réside dans le fait qu’elle pourrait s’appliquer à n’importe quel autre indicateur clé de performance de la fidélité.
Enfin les griefs que nous pouvons faire à notre démarche c’est premièrement qu’elle ne puisse s’appliquer que si nous arrivons à collecter des données pertinentes et deuxièmement c’est qu’elle ne puisse permettre de déterminer exactement les racines de la fidélité ou non des clients.
Section 3 Proposition de solutions
Nous avons vu plus haut que notre démarche présenterait tout au moins deux désavantages à savoir l’absence des données pertinentes et le fait qu’elle repose sur une méthode d’interprétation.
Pour continuer les travaux sur la présente étude nous proposons de réaliser une collecte de données sur le terrain si possible pour un autre indicateur clé de performance que le Churn et de conjuguer avec les techniques d’dentification de la causalité relevant du domaine de l’économétrie pour réellement déterminer les racines de la fidélité client
Conclusion générale
Nous avons montré qu’aujourd’hui dans une situation de contraintes sanitaires sans précédent liée au Covid-19 et caractérisée par un recul du pouvoir d’achat et des changements majeurs dans les habitudes de consommation des consommateurs, il est plus que jamais primordial pour une société B2C de fidéliser ses clients.
Nous avons vu que la fidélisation des clients passait par une accumulation d’expériences clients réussies et agréables. Nous avons montré que la mise en place d’une expérience client de choix passait nécessairement par l’élaboration des politiques de fidélisation efficients basées sur une connaissance accrue en amont des comportements des clients.
Nous avons montré qu’intégrer l’apprentissage automatique dans les programmes de fidélisation client pour une société B2C pourrait être le gage d’un marketing ciblé et personnalisé et cela in fine ne pourrait qu’avoir un impact positif sur l’image de marque de la société et permettrait ainsi un retour sur investissement accru.
Cependant nous pensons que pour vraiment fidéliser un client, il faut avant toute chose être un bon commerçant. Être un bon commerçant est un bel état d’esprit que nous pourrions résumer par le fait de considérer son client comme son invité. Evidemment quand nous recevons des invités chez soi nous leur préparons le terrain, nous faisons tout pour qu’ils se sentent comme chez eux et c’est justement cet état d’esprit qui devrait animer toute société de B2C dans sa relation avec ses clients.
Pour conclure, il n’y a aucun programme de fidélisation qui vaille qui ne soit animé par un bel état d’esprit commerçant.
Bibliographie
Barbaray, C. (2016). Satisfaction, fidélité et expérience client. Paris: DUNOD.
Claeyssen, Y. A. (2011). Le marketing client multicanal : Prospection, fidélisation et reconquête du client Ed. 3. PARIS: Dunod.
Digital, L. R. (2020, 05 31). Le PDG de Carrefour sera rémunéré en partie selon la satisfaction client. Récupéré sur La Revue DU DIGITAL: https://www.larevuedudigital.com/le‐pdg‐de‐carrefour‐ sera‐remunere‐en‐partie‐selon‐la‐satisfaction‐client/
Explain Your Model with the SHAP Values. (2019, 09 14). Retrieved AOUT 3, 2020, from https://towardsdatascience.com/: https://towardsdatascience.com/explain‐your‐model‐ with‐the‐shap‐values‐bc36aac4de3d
Fidelisa. (2017). La fidélisation en 4 temps. Fidelisa.
Flambard, S. (2002). Marketing relationnel : nouvelle donne du marketing. Paris: e‐theque.
GALLEMARD, J. (2017, 10 02). Satisfaction client VS Fidélisation Client, Quelles differences ? Récupéré sur Blog. SMART TRIBUNE: https://blog.smart‐tribune.com/fidelisation‐client‐vs‐satisfaction‐ client
GALLEMARD, J. (2018, 01 09). Les enjeux d’une bonne stratégie de fidélisation de relation client.
Consulté le 07 06, 2020, sur blog.smart‐tribune: https://blog.smart‐tribune.com/strategie‐ fidelisation‐enjeux‐relation‐client
Jumelle, M. (2020, 00 00). Maxime Jumelle. Consulté le 05 6, 2020, sur Maxime Jumelle: https://www.maximejumelle.com/teaching.php
PUGET, Y. (2020, 07 28). Alexandre Bompard (Carrefour) : « Notre performance du premier semestre 2020 est très solide ». Consulté le 07 28, 2020, sur LSA : https://www.lsa‐conso.fr/alexandre‐ bompard‐carrefour‐notre‐performance‐du‐premier‐semestre‐2020‐est‐tres‐solide,355383
Ray, D. S. (2016). MARKETING RELATIONNEL : Rentabiliser les politiques de satisfaction,fidélité,réclamation. Paris: Dunod.
Roder, S. (2019). Guide pratique de l’intelligence artificielle dans l’entreprise : Anticiper les transformations, mettre en place des solutions Ed. 1. PARIS: Eyrolles.
SAINT‐CIRGUE, G. (2020). Consulté le 06 07, 2020, sur machinelearnia: https://machinelearnia.com/
TABLE DES ILLUSTRATIONS
Figure 1: Calcul NPS ( Source: https://blog.smart‐tribune.com/satisfaction‐client‐kpi) 20
Figure 2 :ML Vs IA ( Source: https://www.linkfluence.com/fr/blog/intelligence‐artificielle‐social‐ media) 24
Figure 3: Aperçu jeu de donnees (Source Personnelle: implementation python jupyter) 28
Figure 4: tableau des metadonnees (Source personnelle) 29
Figure 5 : Répartition des clients selon le Churn 31
Figure 6 : Relation Churn & « averagecharges » 32
Figure 7 : RELATION CHURN & « Tenure » 33
Figure 8 : RELATION CHURN & « SeniorCitizen » 33
Figure 9 : RELATION CHURN & « Gender » 34
Figure 10 : RELATION CHURN & « Partner » 34
Figure 11: RELATION CHURN VS « dependents 35
Figure 12 : RELATION Churn & « MultipleLines » 35
Figure 13 : RELATION CHURN & « Internet Service » 36
Figure 14 : RELATION CHURN & « Contract » 36
Figure 15: RELATION CHURN & « service internet optionnel » 37
Figure 16: RELATION CHURN & « AVERAGESCHARGES & « CONTRACT »& »PaymentMethod » 38
Figure 17 : RELATION CHURN & « PaymentMethod » 39
Figure 18 : Corrélation entre les variables explicatives 39
Figure 19: Entrainement et évaluation du modèle RandomForest 41
Figure 20 : Entrainement et évaluation du modèle XGboost 42
Figure 21: Validation de modèle XGboost Vs RandomForest 43
Figure 22: Graphique d’importance des variables explicatives 44
Figure 23 : Summary Plot ‐ Variables explicatives 45
Figure 24: Encodage des variables qualitatives (Source personnelle) 46
Figure 25 : Dependence Plot de la variable « Gender » 47
Figure 26: Dependence Plot de la variable « SeniorCitizen » 48
Figure 27 : Dependence Plot de la variable « Partner » 48
Figure 28 : Dependence Plot de la variable « Dependents » 49
Figure 29 : Dependence Plot De la variable « tenure ». 50
Figure 30 : Dependence Plot de la variable « MultipleLines » 50
Figure 31 : Dependence Plot de la variable « InternetService » 51
Figure 32 : Dependence Plot de la variable « OnlineSecurity » 52
Figure 33 : Dependence Plot de la variable « OnlineBackup » 52
Figure 34 : Dependence Plot de la variable « DeviceProtection » 53
Figure 35 : Dependence Plot de la variable « TechSupport » 54
Figure 36 : Dependence Plot de la variable « StreamingTV » 54
Figure 37 : Dependence Plot de la variable « Contract » 55
Figure 38 : Dependence Plot de la variable « PaperlessBilling » 56
Figure 39: Dependence Plot de la variable « PaymentMethod » 56
Figure 40 : Dependence Plot de la variable « AveragesCharges » 57
Figure 41:Logistic Regression (Source :http://towardsdatascience.com/logistic‐regression‐explained‐ 9ee73cede081) 58
Figure 42 : Individual Force Plot du client N° 6650 59
Figure 43 : Individual Force Plot du client N° 200 60
Figure 44 : Individual Force Plot du client N° 20 60