
3.1.5. RDF Site Summary (RSS)
Cette section présente le modèle et la syntaxe de RSS de telle sorte que le lecteur puisse s’approprier ce cadre38 et l’utiliser dans un système de gestion de contenu et en particulier un système de gestion de site web. Elle est aussi une illustration de l’utilisation de RDF (cf. section 2.3.3) et des méta données de Dublin Core (cf. section 2.3.2) et constitue une suite logique à ce rapport. C’est aussi un exemple concret d’illustration de la section précédente (3.1.4 « EDI et syndication »).
3.1.5.1. Introduction
L’objectif de RSS est de permettre l’alimentation d’un site Web avec des composants documentaires provenant d’un autre site web.
Il a été initialement mis en œuvre pour afficher les entêtes de nouvelles39 de sites Web d’informations et notamment pour les agréger. Ainsi sur une même page, à propos d’un thème particulier, sont regroupées des entêtes de nouvelles provenant de plusieurs sites web distincts. Chaque site source nourrit le site fédérateur40. Simple en apparence et dans ses spécifications, RSS est très puissant et est utilisé dans de nombreux portails.
Un des fondements de RSS à partir de la version 1.0, comme son nom développé nous l’indique (RDF Site Summary), est la mise en œuvre de RDF pour réaliser un document RSS. RSS s’appuie donc aussi sur la notion de domaines nominaux (namespaces – cf. section 2.3.3.1). RSS est un exemple d’application et de l’extensibilité de RDF à travers l’utilisation des schémas RDF (voir annexe 5.1 « Schéma RDF des documents RSS »).
La version actuelle de la norme RSS est 1.0. Elle est compatible avec les versions précédentes (0.91 et 0.9 qui n’utilisait pas RDF). RSS est un format de syndication à vocation normative développé par un groupe indépendant : le groupe de travail RSS41. Elle ne devrait plus évoluer, seuls de nouveaux modules permettent de l’étendre.
36 système source : système d’origine où sont créés et maintenus les documents.
37 Syndication : terme d’origine anglo-saxonne. Certains parlent parfois de fédération ou d’agrégation.
38 Cadre : référence au terme anglo-saxon « framework », qui est aussi traduit par ossature, squelette…
39 Nouvelles : news, annonces, brèves…
40 D’où le terme anglais “RSS feed”, utilisé comme concept RSS.
RSS n’est donc pas prévu initialement pour échanger des documents, mais plutôt les méta données des documents. Cependant, avec la version 1.0 et son mécanisme d’extension à travers l’utilisation et le rajout possible de modules, il est théoriquement possible d’échanger des documents. Un module est un schéma RDF complémentaire. En tant qu’application de RDF, RSS montre bien que ce premier convient bien à l’échange de méta données, comme cela est son objectif (cf. section 2.3.3.1). Concrètement, dans le CMS important les composants documentaires, seul le fichier RSS et donc les méta données sont intégrées. Le document n’est relié que par un lien (un URI) permettant d’accéder au document dans le système source.
Le format RSS est concrètement un document XML qui obéit à une structure de base. Les modules permettent d’enrichir la structure de base [44] [45]. Nous allons maintenant aborder ces éléments du format de syndication RSS.
3.1.5.2. Structure de base
La structure de base d’un document RSS est la suivante [46], dans l’ordre :
– déclaration XML,
– le conteneur,
– description du canal,
– description de l’image (optionnelle),
– description du ou des articles,
– description du champ de saisie (optionnelle).
Cette structure est toujours la même dans les documents RSS. Elle est conforme au schéma RDF des données RSS (annexe 5.1 « Schéma RDF des documents RSS »). Aussi, un exemple [44] permet d’aborder chaque élément de la structure.
xmlns:rdf= »http://www.w3.org/1999/02/22-rdf-syntax-ns# »
xmlns= »http://purl.org/rss/1.0/ »
>
http://xml.com/pub
XML.com features a rich mix of information and services
for the XML community.
/>
http://www.xml.comhttp://xml.com/universal/images/xml_tiny.gif http://xml.com/pub/2000/08/09/xslt/xslt.html
Processing document inclusions with general XML tools can be
problematic. This article proposes a way of preserving inclusion
information through SAX-based processing. http://xml.com/pub/2000/08/09/rdfdb/index.html
Tool and API support for the Resource Description Framework
is slowly coming of age. Edd Dumbill takes a look at RDFDB,
one of the most exciting new RDF toolkits.
Search XML.com’s XML collection
s http://search.xml.com
Cet exemple requiert bien sûr des commentaires supplémentaires. Notons déjà que chaque élément est décrit par des propriétés title, link, description. La propriété link contient une URL pointant vers l’élément décrit. La propriété description est optionnelle (pour l’élément item), absente pour l’élément image ou obligatoire pour les autres éléments (channel et textinput).
L’élément channel définit le site ou la page web (la ressource) syndiquée. Un fichier RSS décrit un « canal » RSS. L’élément channel contient une référence aux éléments associés : image, items, textinput. On peut penser qu’il s’agit d’une redondance puisqu’on les trouve dans la suite du document RSS de l’exemple, mais c’est surtout une facilité pour des traitements complémentaires.
L’élément image permet d’associer une image au canal RSS dans le site Web fédérateur. L’image doit être normalement d’une dimension de 88×33 pixels.
L’élément item définit le composant documentaire recherché pour la syndication. Il peut être répété 15 fois au maximum dans les versions 0.9x de RSS. C’est le cœur du document RSS.
Enfin l’élément textinput permet d’associer un champ de saisie à une URL qui reçoit via la méthode HTTP GET la valeur de la variable de requête saisie. Cet élément est l’objet de controverses dans le groupe de travail RSS41. Il est utilisé traditionnellement comme boîte de recherche ou comme champ de formulaire.
Comme cela a été dit. Cela paraît simple et ça l’est. Mais cela offre déjà des mécanismes d’agrégation (fédération) puissant. Cependant, il est possible de les étendre encore via l’utilisation des modules RSS, objet du chapitre suivant.
3.1.5.3. Modules
La structure de base d’un document RSS peut être enrichie grâce à l’utilisation des modules RSS [47]. La modularisation est basée sur la capacité d’extension de RDF (cf. 2.3.3.3 « Schémas RDF ») et offre à RSS la capacité d’être étendu.
Les modules reconnus comme normes associées à RSS 1.0 par ses auteurs sont les suivants :
– Dublin Core,
– Syndication,
– Content.
Cependant, le module « Content » n’est pas inclus par défaut dans RSS 1.0 alors que les modules « Dublin Core » et « Syndication » le sont.
Un exemple d’enrichissement de la structure d’un « canal » RSS par l’utilisation des modules est donné en annexe 5.2 intitulée Exemple de fichier RSS de syndication, sauf pour le module « Content » qui ne sera pas illustré.
Le module Dublin Core
RSS adopte le schéma de méta données de Dublin Core pour définir un ensemble de méta données normalisées associé à RSS 1.0 [48]. Tous les éléments pour comprendre son utilisation sont contenus dans les sections 2.3.2 « Dublin Core Metadata Initiative (DCMI) » et 2.3.3 « Resource Description Framework (RDF) ».
Le module Syndication
Ce module [49] est conçu pour fournir un exemple de variables de fréquence de mise à jour à ceux qui utilisent RSS pour agréger des informations. Il contient 3 éléments : updatePeriod, updateFrequency et updateBase.
L’élément updatePeriod définit la période au delà de laquelle le « canal » est mis à jour. C’est à dire qu’il définit la période de rafraîchissement du fichier RSS importé par le CMS « agrégateur ». Les valeurs acceptées sont hourly, daily, weekly, monthly, yearly, soit en français, toutes les heures, quotidiennement, hebdomadairement, mensuellement et annuellement.
L’élément updateFrequency est utilisé pour décrire la fréquence des mises à jour en relation avec la valeur définie pour la période de mise à jour. Un entier positif indique combien de fois dans cette période le « canal » est mis à jour. Par exemple, une période quotidienne et une fréquence de mise à jour de « 2 » indiquent que le canal RSS est mis à jour deux fois par jour.
Enfin, l’élément updateBase définit, en concert avec les deux éléments précédent, la date et l’horaire de la mise à jour de la publication. L’élément updateBase permet de calculer cette date. On s’aperçoit ici que RSS a bien été conçu et utilisé pour la gestion de site web. Le format de date se conforme au format de date42 définit par le W3C.
Ces éléments montrent que RSS est prévu pour que cela soit le site fédérateur qui interroge le site d’origine du document. Cela a cependant un coût important au regard de ce qu’il serait si, à l’inverse, il était prévu que cela soit le site d’origine qui mette à jour le site « syndicateur » uniquement en cas de mise à jour du composant documentaire original.
Le module « content »
C’est un module qui permet de répliquer le contenu effectif du site web fédéré et qui permet de définir les formats du contenu. La partie concernant les contenus encodés (content:encoded) n’est pas « normalisée » par le groupe de travail RSS [50].
Aussi ce module définit un seul élément central : item. que nous écrivons content:item afin de le diffrencier de l’élément item de la structure de base de RSS (cf. section 3.1.5.2 « Structure de base »). Les éléments content:item sont inclus dans un élément englobant content:items qui est lui-même un sous-élément de l’élément item ou de l’élément channel de RSS.
Un élément content:item peut inclure les sous-éléments suivants : content:format, content:encoding, rdf:value (voir Tableau 7 : Propriétés RDF page 112 pour la définition de rdf:value).
L’élément content:format est obligatoire. C’est un élément vide (au sens XML) contenant un attribut rdf:resource qui pointe vers une URI représentant le format de l’élément content:item. La meilleure pratique suggérée est d’utiliser la liste des « natures » RDDL43 (Resource Directory Description Language). RDDL définit les valeurs possibles de la nature d’une ressource référencée de la manière suivante44 : « Quand une ressource référencée est un document XML et que sa nature peut-être déduite de l’URI du domaine nominal de l’élément racine du document XML, l’URI de domaine nominal est la nature de la ressource référencée. Quand une ressource référencée n’est pas un document XML et que sa nature peut être déduite de son type MIME45, la nature de la ressource référencée est obtenue en attachant le type de contenu46 au préfixe http://www.isi.edu/in-notes/iana/assignments/media-types/ ». Cette référence à tout type de document XML et aux types de contenu MIME offre une couverture largement acceptable et presque universelle des types de documents existants dans le monde. Il semble cependant qu’il y ait là une ambiguïté entre le « type de document » et le « format » tel qu’ils sont décrit par le DCES47.
L’élément rdf:value est obligatoire si aucune URI n’est définie dans l’attribut rdf:about de l’élément content:item. L’élément contient le contenu du composant documentaire. C’est donc le cœur du module et en tout cas son objet. Il est encodé comme spécifié dans l’élément content:encoding. Si le contenu est en XML et que l’élément content:encoding ne précise rien, alors l’attribut rdf:parseType doit avoir la valeur « Literal » (rdf:parseType= »Literal ») afin de respecter la syntaxe RDF.
content:encoding est un élément optionnel vide (au sens de XML) avec un attribut rdf:resource pointant vers une URI qui doit représenter l’encodage du contenu de content:item.
A travers les exemples des spécifications du module « content » [50] et la préférence affichée pour l’utilisation de valeurs contenues dans la liste RDDL des natures44, on s’aperçoit avec ce dernier élément (content:encoding) que le module « content » est surtout prévu pour échanger des documents de type XML ou HTML, c’est à dire des formats de documents contenus dans des serveurs web.
3.1.5.4. Conclusion
RSS est un exemple de format de syndication de documents issu et utilisé principalement pour la gestion de site web et par extension dans les portails. La structure de base de RSS permet la réplication des méta données des composants documentaires. Ces méta données peuvent être étendues de manière non-limitative grâce aux modules. RSS est aussi assez complet pour pouvoir autoriser la réplication des documents eux-mêmes grâce au module « Content ».
RSS est donc un exemple intéressant de protocole d’EDI pour la gestion de contenu qui illustre l’échange de méta données et de composants documentaires. Le respect de XML et de RDF par RSS fait qu’il est par ailleurs largement substituable par un format propriétaire offrant les mêmes services.
3.1.6. Droits d’accès et travail collaboratif
Ce sujet fait partie de la section sur le « Système de collecte » car il est une des composantes indispensables des systèmes de collecte. Concernant les droits d’accès, Il est aussi relié à la publication des documents, notamment dans les systèmes où le contenu n’est pas séparé de la présentation et donc de la publication.
3.1.6.1. Droits d’accès
Les droits d’accès de base à un document sont simples : lecture (R), écriture (W), suppression (D)48. En lecture, un utilisateur a accès à un composant documentaire mais ne peut pas le modifier ou encore le mettre à jour, ce qu’il peut faire s’il a les droits d’écriture. Le droit de suppression est assez explicite. Les droits d’accès peuvent être spécifiés dans une matrice ad hoc dite matrice des droits d’accès. Il s’agit d’un tableau reprenant les variables utilisateurs, groupe de travail et droits d’accès.
On doit donc introduire ici la notion de groupe de travail. Un groupe de travail est composé d’utilisateurs. Les droits peuvent être affectés à un utilisateur ou à un groupe de travail. Si un utilisateur fait partie d’un groupe de travail, il hérite des droits du groupe.
Les droits d’accès peuvent être définis document par document. Mais il est beaucoup moins complexe de définir les droits en fonction des types de documents (cf. 2.1.2.2 « Type de document : DTD / XML schema / Template »).
La traduction logique d’une matrice des droits peut être représentée par une liste ACL (Access Control List).
Par ailleurs, une acceptation commune et la meilleure pratique sont de centraliser les données des utilisateurs et des groupes de travail dans des annuaires LDAP (Lightweight Directory Access Protocol). La plupart des logiciels de CMS propose une connexion aux annuaires LDAP afin de gérer les utilisateurs dans l’application de gestion de contenu.
3.1.6.2. Travail collaboratif : workflow
Le travail collaboratif, et plus précisément le workflow, est un sujet à part entière de la gestion de contenu, et en l’étendant, qui s’applique à la gestion des processus d’affaire (Business Process Management – BPM). Concernant la gestion de contenu, le travail collaboratif est défini par les chaînes d’édition. Il s’agit du processus qui va de la création à la publication d’un document.
Un workflow est défini par des étapes : du démarrage du processus à sa terminaison. Chaque étape est déterminée par le passage d’un état de l’objet du workflow à un autre. Une tâche consiste à faire passer l’objet (en clair, le document) d’un état à un autre. La tâche est réalisée par un utilisateur ayant le rôle adéquat.
Le processus d’édition le plus simple et le plus fréquent est le suivant. L’auteur crée (ou met à jour) un document, l’éditeur le valide (ou le refuse) puis le document est publié automatiquement. Certains documents réclament toutefois une organisation plus complexe (notamment les documents composites).
Les états de base d’un document dans une chaîne éditoriale est : crée ou mis à jour, soumis (à la validation de l’éditeur), validé ou refusé et publié. Un document validé est souvent publié automatiquement suite à sa validation, mais peut parfois être publié ultérieurement.
Un workflow peut être exécuté séquentiellement (les tâches sont effectuées les unes après les autres) ou en parallèle (les tâches sont effectuées en même temps, indépendamment l’une de l’autre). Une tâche peut être affectée à plusieurs utilisateurs et ne nécessiter que l’intervention de l’un d’entre eux.
Par exemple, un document peut être soumis à validation à plusieurs éditeurs et seule une validation par un des éditeurs suffira pour que le document passe à l’étape suivante.
Il faut introduire ici une nouvelle notion : celle de rôle. On affecte dans un workflow une tâche à un rôle. On affecte aussi à un utilisateur un rôle dans un groupe de travail. Donc finalement, un utilisateur hérite de ses droits dans un groupe de travail à travers l’affectation d’un rôle.
Ce rôle basiquement consiste en une opération équivalente aux droits mentionnés ci-dessus, à savoir la lecture, l’écriture et / ou la suppression d’un document. Mais ce rôle peut être plus complexe, à savoir que s’il requiert un droit de base, il peut effectuer des opérations spécifiques. Dans ce contexte, l’utilisateur peut-être aussi un programme informatique. Par exemple, c’est peut-être un automate qui va effectuer certains pré-traitements comme la catégorisation du document, sa traduction en langue étrangère, sa correction orthographique. Le rôle peut ne concerner aussi qu’uniquement les méta données. C’est à dire, par exemple, qu’un utilisateur, typiquement un documentaliste, peut n’avoir le droit d’écriture que sur plusieurs méta données et que le droit d’écriture sur le composant documentaire.
Dans le cadre d’une application de gestion de contenu, les rôles les plus fréquemment rencontrés de manière basique sont l’auteur (aussi appelé rédacteur), l’éditeur (qui valide les documents avant publication, encore appelé approbateur) et bien sûr l’administrateur. Le rôle de l’administrateur (parfois appelé coordinateur) a trait à la gestion des groupes de travail et contrôle un certain nombre de paramètres à ce niveau là. Il ne faut bien sûr pas le confondre avec l’administrateur de l’application. L’administrateur ne rentre pas dans les processus
Un autre rôle, souvent implicite, est celui de lecteur.
Le rôle doit être théoriquement défini au niveau de chaque composant documentaire. La définition du rôle peut être une méta donnée d’application (cf. sections 2.3.1.2 « Données d’application » et 2.3.1.4 « Données de personnalisation »).
Le rôle est repris aussi dans les spécifications de la chaîne d’édition. On peut spécifier une chaîne d’édition à l’aide d’un graphe ou encore d’un diagramme état-transition. La figure suivante illustre cela.
Figure 2 : exemple de diagramme état-transition de spécification d’une chaîne d’édition
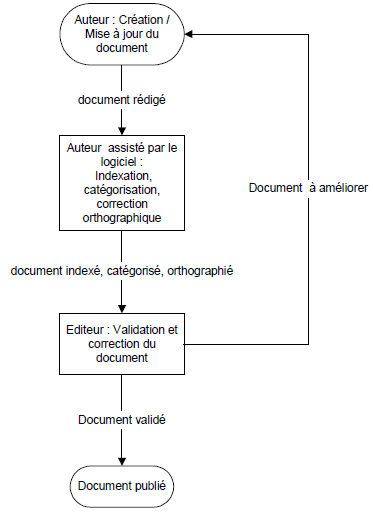
Les autres composantes du travail collaboratif sont le courrier électronique, les forums de discussion, la conférence électronique (vocale ou vidéo), le tableau blanc partagé, les outils d’annotation de documents…
Voyons ensuite, sans transition, maintenant que le système de collecte d’un CMS a été vu, en quoi consiste un système de gestion de contenu.
Lire le mémoire complet ==> (Les systèmes de gestion de contenu : description, classification et évaluation)
Mémoire présenté en vue d’obtenir le DIPLOME D’INGENIEUR C.N.A.M. en informatique
Conservatoire National Des Arts Et Métiers – Paris