
Mesure de la qualité d’un modèle de traduction
4.5 Mesure de la qualité d’un modèle de traduction
Il existe différentes manières d’évaluer la qualité d’un modèle de traduction. Une possibilité consiste à évaluer globalement la performance d’un engin de traduction au complet.
Nous reviendrons sur ce mode d’évaluation dans le chapitre 6 et nous intéressons dans cette section à l’évaluation directe bien que critiquable du seul modèle de traduction.
Nous utilisons pour cela la perplexité qui représente le nombre moyen d’ »hésitations » qu’aurait le modèle s’il devait traduire un texte de manière identique à une traduction de référence. Formellement, la perplexité est donnée par :
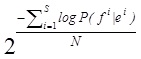 (4.1)
(4.1)
Où la probabilité P(fi|ei) est donnée par le modèle de traduction évalué. N est le nombre de mots du corpus, S le nombre de paires de phrases. Les algorithmes d’entraînements implémentés dans GIZA optimisent les paramètres des modèles de manière à minimiser la perplexité.
Il est important de noter que la perplexité d’un modèle ne reflète que très indirectement son aptitude à bien traduire ; elle nous donne une indication de son aptitude à reconnaître que deux phrases sont (ou ne sont pas) en relation de traduction selon un modèle mesuré sur le corpus d’entraînement.
Chaque modèle a été entraîné à l’aide de sept itérations auxquelles s’ajoute une itération pour transférer les paramètres d’alignement du modèle 2 au modèle 3 (les deux modèles possèdent en effet les mêmes tables de paramètres de transfert et des distributions d’alignement inversées).
Lors de l’initialisation des paramètres du modèle 1, la perplexité est de 66 863.4. Après la première itération, elle passe à 250.8 et tombe à 91.1 à la fin de la 7ème itération. Les itérations sur le modèle 2 baissent la perplexité à 40.9 après 7 itérations (figure 14).
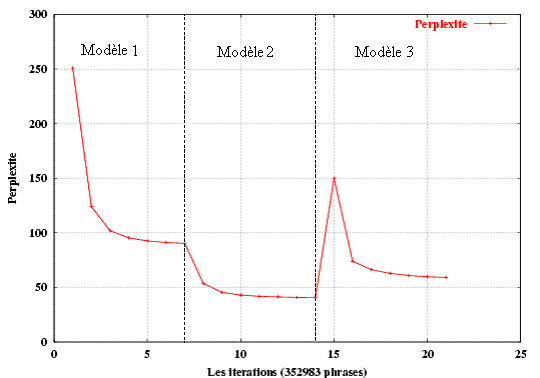
Figure 14: La perplexité par rapport aux itérations des modèles 1, 2 et 3 entraînés sur un corpus de 352 983 paires de phrases françaises / anglaises (la déficience du modèle 3 est démontré par une croissance brusque de la perplexité).
D’autre part, la perplexité décroît après chaque itération sauf quand on transite du modèle 2 au modèle 3 (voir la figure 14). Dans ce cas, ce saut ne justifie pas que le modèle 2 est meilleur. [Brown et al, 1993] disent que c’est normal et expliquent les causes de ce saut (voir [Brown et al, 1993] pour plus de détails). De plus, les expérimentations ont montré le modèle 3 est meilleur que le modèle 2.
4.6 Quelques exemples et chiffres pour commenter les résultats
Dans cette section on présente plusieurs exemples pris au hasard afin d’illustrer les résultats qu’on a obtenus avec les différents modèles. On montre les alignements, les probabilités de transfert et les fertilités.
4.6.1 Les alignements des mots
Dans les exemples qui suivent, pour chaque modèle, on présente le meilleur alignement de mots obtenu pour cette paire de phrases :
Canadian charter of rights and freedoms (phrase anglaise de 6 mots).
La charte canadienne des droits et libertés (phrase française de 7 mots).
Modèle 1:

Figure 15: Le meilleur alignement obtenu pour cette paire de phrases par IBM1.
Dans cet exemple, on remarque que le mot « charter » est associé à deux mots « la charte « . On appelle ce genre d’association « fertilité indirecte » du modèle 1 (fertilité de charter est égale à 2) cependant « of » n’a pas été traduit par aucun mot (fertilité 0).
Modèle 2:

Figure 16: Le meilleur alignement obtenu pour cette phrase par IBM2.
Le modèle 1 suppose que toutes les positions sont équiprobables, cependant le modèle 2 accorde des probabilités d’alignement aux positions des mots français et anglais.
C’est une explication possible du fait que dans le cas de l’alignement obtenu par le modèle’2, le mot en première position se connecte à la première position (canadian -> la).
Modèle 3:

Figure 17: Le meilleur alignement obtenu pour cette phrase par IBM3.
Dans cet exemple, on voit l’effet produit par les paramètres de fertilité. Par exemple, le mot « charte » est associé à un seul mot (fertilité 1) toutefois il n’a trouvé aucune traduction pour le mot « la » (fertilité 0). Les mots « la » et « des » sont associés à NULL (e0) et ce qu’on appelle des mots spurious.
4.6.2 Les probabilités de transfert
Nous comparons les modèles de traduction à l’aide des paramètres de transfert sur des exemples que nous avons mentionnés dans la section précédente. Nous aimerions montrer que le modèle 3 est le meilleur.
| Modèle 3 | Modèle 2 | ||
| f | t(f|e) | f | t(f|e) |
| canadienne | 0.259923 | canadienne | 0.2025 |
| canadiens | 0.251528 | canadiens | 0.194901 |
| canadien | 0.216328 | canadien | 0.176973 |
| canadiennes | 0.118263 | canada | 0.0852405 |
| canada | 0.107003 | canadiennes | 0.0772148 |
| notre | 0.0113057 | les | 0.0640237 |
| nos | 0.0101566 | du | 0.0479771 |
| canadian | 0.0072526 | la | 0.0288901 |
| pays | 0.00317151 | des | 0.0286695 |
| nationale | 0.00168392 | de | 0.0197803 |
Tableau 3: Les dix premières probabilités de transfert du mot « canadian » (modèle 2 et 3) prises des résultats d’entraînement sur un corpus de 1.6 millions de phrases.
On observe dans l’exemple du tableau 3 que les deux modèles 2 et 3 donnent des associations pertinentes. De manière intéressante, on observe également que le modèle 3 assigne des probabilités plus élevées aux mots les plus pertinents.
Le filtre (seuil de 10-8) qui élimine les associations les moins probables est partiellement responsable de cela. En effet, le modèle 2 assigne à « canadian » 122 mots, alors que le modèle 3 en considère seulement 75. Ainsi on peut bien comprendre pourquoi les modèles alignent le mot « canadienne » à « canadian » de l’exemple précédent.
Un autre exemple, prenons le mot « rights »
| Modèle 3 | Modèle 2 | ||||
| f | t(f|e) | Φ | n(Φ|e) | f | t(f|e) |
| droits | 0.796545 | 0 | 0,0454826 | droits | 0.608039 |
| des | 0.085716 | 1 | 0,8399 | des | 0.190462 |
| droit | 0.056123 | 2 | 0,113953 | les | 0.0988315 |
| déclaration | 0.0115531 | 3 | 0,00031607 | droit | 0.0307268 |
| aux | 0.0066727 | 4 | 0,00021108 | déclaration | 0.0106583 |
| ceux | 0.00609777 | 5 | 0,000135305 | la | 0.00914235 |
| leurs | 0.00471072 | 6 | 0,00011211 | personne | 0.00824262 |
| charte | 0.00280203 | 7 | 0 | leurs | 0.00505768 |
| les | 0.0024573 | 8 | 0 | aux | 0.00494197 |
| respecter | 0.00185838 | 9 | 0 | de | 0.00433437 |
Tableau 4: Les dix premières probabilités de transfert du mot « rights » (modèle 2 et 3) entraîné sur un corpus de 1.6 millions paires de phrases. Soit n(Φ|e) la probabilité que le mot e a une fertilité Φ.
Le modèle 2 traduit le mot « rights » de cette phrase (canadian charter of rights and freedoms) par les deux mots français « des droits », cependant le modèle 3 traduit ce mot par un seul mot « droits ».
On peut expliquer la différence entre ces deux modèles par le fait que le modèle 3 concentre une masse de probabilités sur « droits » plus que le modèle 2, et ceci, grâce aux fertilités intégrées dans l’équation du modèle 3 (tableau 4). Noter que la probabilité de fertilité est nulle à partir de 7 car on a autorisé une fertilité maximale de 5 durant l’entraînement.
4.6.3 Les fertilités
Le mot anglais « update » se traduit habituellement par le terme « mise à jour » ou « mettre à jour ». Les probabilités de transfert peuvent capturer cette information en associant ces mots français au mot anglais avec une forte probabilité.
Les distributions de probabilités nous permettent d’apprécier sur cet exemple l’information que capture le modèle 3. Ici, le modèle découvre que « update » se traduit de manière très probable par 3 mots.
| f | t(f|e) | La fertilité Φ | n(Φ|e) | |
| jour | 0.202269 | 0 | 0.0963158 | |
| à | 0.128631 | 1 | 0.24774 | |
| mettre | 0.110322 | 2 | 0.242352 | |
| mise | 0.0673782 | 3 | 0.362265 | |
| moderniser | 0.0540367 | 4 | 0.0313557 | |
| dire | 0.0164854 | 5 | 0.0192533 | |
| courant | 0.01618 | 6 | 0.000218907 | |
| modernisation | 0.0137019 | 7 | 0 | |
| mis | 0.0134613 | 8 | 0 | |
| actualiser | 0.0107915 | 9 | 0 |
Tableau 5: Les probabilités de transfert et de fertilité du mot « update ».
Le tableau 5 nous montre que la fertilité 3 est la plus probable et les probabilités de transfert offrent aussi la plupart des traductions (jour, à, mettre, mise, etc.…)
Certains mots anglais n’ont pas de traduction exacte en français comme par exemple le mot « nodding » (tableau 6). On retrouve par exemple les traductions suivantes: (Il fait signe que oui | He is nodding), (Il fait un signe de la tête | He is nodding), (Il fait un signe de tête affirmatif | He is nodding) ou (Il hoche la tête affirmativement | He is nodding). La fertilité élevée de ce mot est capturée par le modèle 3 (voir tableau 6).
| f | t(f|e) | La fertilité Φ | n(Φ|e) | |
| signe | 0.17294 | 0 | 0.0129514 | |
| tête | 0.168938 | 1 | 0.218677 | |
| oui | 0.0739652 | 2 | 0.212233 | |
| que | 0.0736777 | 3 | 0.220905 | |
| fait | 0.0735548 | 4 | 0.324023 | |
| hoche | 0.0637272 | 5 | 0.00819289 | |
| hocher | 0.0333808 | 6 | 0.00301704 | |
| un | 0.0321521 | 7 | 0 | |
| assentiment | 0.0289505 | 8 | 0 | |
| me | 0.0178129 | 9 | 0 |
Tableau 6: Un exemple des mots anglais ayant une large fertilité « nodding ».