Qu’est-ce qu’un moteur de recherche ?
Chapitre 1 – Les moteurs de recherche
Trois possibilités s’offrent à l’internaute pour trouver un site : soit il connaît le nom de domaine* et le tape directement dans son navigateur*, soit le lien* est enregistré dans ses favoris. Il peut aussi utiliser des sites où se retrouve concentrée et organisée l’information : les outils de recherche [Carlier, 2000, p. 170, (01)]. Ceux-ci peuvent être généralistes ou spécialisés sur un thème donné.
1.1. Présentation des outils de recherche
1.1.1. Différence entre annuaire et moteur de recherche
Annuaire
Appelé également guide ou répertoire, un annuaire est « un catalogue de sites, hiérarchisés par catégories ou rubriques. » [Carlier, 2000, p. 171, (01)]. Les thèmes sont organisés du plus général au plus particulier.
Il est constitué d’un ensemble de fiches descriptives présentant l’URL*, le titre et un résumé du site indexé, parfois son origine géographique, le public visé et la langue employée. Des « documentalistes », également appelés « netsurfeurs », sont chargés de visiter, évaluer puis classer les sites soumis dans les rubriques les plus appropriées. Ils se réservent le droit de modifier les données transmises (commentaires, titre, rubriques proposées) [Andrieu, 2000, p. 348, (02)].
Les annuaires proposent deux modes d’interrogation : (1) via le mode de navigation hiérarchique dans la classification (catégories, sous-catégories, rubrique, liste) ; (2) sous forme de requête à l’image des moteurs de recherche.
Parmi les principaux annuaires francophones, nous pouvons citer le Guide de Voila, l’Open Directory Project, Lycos France, Yahoo! France et Nomade.
Moteur de recherche
Un moteur de recherche est un outil constitué d’un ensemble de robots* logiciels (appelés agents*, aspirateurs, araignées* ou robots en français et spiders*, wanderers, crawlers* en anglais).
Ces programmes de navigation parcourent le Web de lien en lien de manière continue en indexant automatiquement le contenu des pages visitées [Chu, 2003, p. 96, (03) ; Andrieu, 2005, p. 8-10, (04)].
Méta-moteur
Les outils de recherche d’information, méta-moteurs* (Metacrawler, Kartoo)1 et logiciels (Copernic, Strategic Finder), interrogent simultanément une sélection de moteurs. Ils classent et exposent les résultats de ces recherches sur leur propre interface.
1.1.2. Les principaux outils de recherche francophones
D’après une étude de l’institut Mediamétrie2, la France comptait 24,3 millions d’internautes soit 46,9 % de la population âgée de 11 ans et plus en juillet 2005. Cette même étude révèle la présence de quelques moteurs de recherche parmi le « Top 30 français » des sites les plus consultés (hors applications)3 dont, en tête de liste Google, suivi de MSN (3e) et Yahoo ! (6e).
La société de référencement 1ère position propose chaque mois ses analyses sur les statistiques fournies par l’outil de mesure d’audience Xiti. Celles-ci permettent de dresser le « Top 10 » des moteurs de recherche majeurs sur le marché, dont une vision synthétique est proposée à travers ce tableau :
Tableau 1 : “Top 10” des moteurs de recherche en fonction des parts de trafic généré (Juillet 2005)
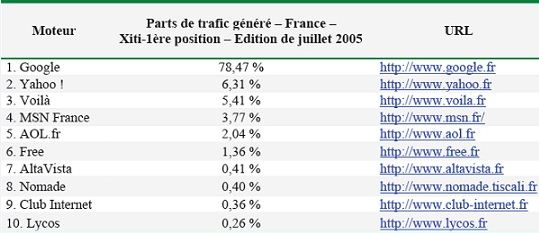
Google et Yahoo ! représentent à eux seuls 84,78 % du marché français, le premier demeurant toutefois le leader incontesté des moteurs de recherche sur le Web avec 78,47 % du volume total généré en juillet 2005. Les autres moteurs de recherche grappillent quelques internautes mais leur part reste dérisoire face à la suprématie de leur puissant concurrent.
Les moteurs de recherche ont relégué les annuaires (Yahoo !4, Voilà5, Lycos6 ) aux oubliettes, ces derniers ne générant qu’un trafic ridicule. Seul l’Open Directory Project7, utilisé par Google résiste encore. Il faut dire qu’il est basé sur un modèle singulier : les évaluateurs sont tous bénévoles.
1.2. Principe de fonctionnement d’un moteur de recherche
Le robot d’un moteur de recherche est en fait « […] un programme qui effectue des recherches automatisées sur Internet. Il parcourt l’ensemble des fichiers constituant un site, emmagasine les informations dans l’index* et classe les mots-clés* et le texte de chaque page qu’il trouve. » [Chu, 2003, p. 96, (03)].
Le fonctionnement d’un moteur de recherche se découpe donc en trois phases, que nous allons, dès à présent, détailler :
- 1) les robots explorent le Web et collectent des informations.
- 2) les robots transmettent les données à l’indexeur. Ce dernier est chargé d’extraire les informations nécessaires à l’indexation tels que les éléments visibles de la page, les mots- clés, les liens et autres métadonnées* [Calishain & Dornsfet, 2003, p. 318, (05)].
- 3) le site est inséré dans la base de données du moteur. Suite à une requête effectuée sur une interface de recherche, les résultats sont restitués sous la forme d’une liste ordonnée où ils sont classés en fonction de leur pertinence (ranking) [Andrieu, 2005, p. 9, (04)].
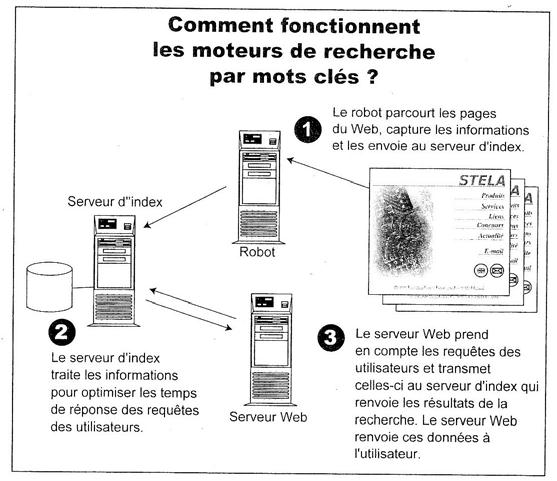
Comment fonctionnent les moteurs de recherche par mots-clés ?
La capture des pages se déroule en trois phases : le robot parcourt le web et envoie les pages au serveur d’index qui sert de référence au serveur web abritant l’interface utilisateur.
Source : Andrieu, 2000, p. 313, (02), avec son aimable autorisation
Les robots ne traitent pas tous les sites de la même manière. Ils explorent plus fréquemment les sites à fort trafic ou à fort taux de renouvellement des contenus aux dépens des pages « statiques » [Andrieu, 2005, p. 10, (04)].