L’algorithme DP : Implémentation et Problèmes rencontrés
5.1.4 Implémentation
Entrée : f1…fj…fJ
Choisir une longueur maximale : Imax
Sélectionner les vocabulaires actifs.
Initialiser la table de recherche Space
Pour toutes les positions cibles i=1,2,…,Imax
. Pour toutes les positions sources j=1,…J
. . Pour toutes les hypothèses H dans Space(i,j)
. . . cv=couverture de l’hypothèse.
. . . Mise à jour des positions libres.
. . . Pour toutes les positions libres k varie de 1 à J.
. . . . Pour tous les mots associés e au mot source fk
. . . . . S=0
. . . . . Pour les fertilités f de 1 à min(J,MAX_FERTILITE)
. . . . . . S+= score H+log (P(fk|ei))+log(P(ei|ei-1,ei-2))+log(a(i|k,l,m))
. . . . . . Mise à jour dans space(k,j+1) l’hypothèse(mot,cv,f,S,Mot Précédant=i,j)
. . . Pour tous les mots de l’ensemble de vocabulaire actif
. . . . S= score H+log(P(ei|ei-1,ei-2))+log(a(0|k,l,m))
. . . . Mise à jour dans space (i, j+1) l’ hypothèse(mot, cv, f, S, Mot Précédant=i,j)
Chercher le score maximum et backtracking:
Pour tous les i de 1 à Imax
. Pour toutes les hypothèses H dans Space(i,j)
. . S=Score H+P(J|i)
. . Si((c==J) et (s>maxs) alors
. . . maxs =s
. . . (maxi, maxj, ,maxe)=(i,j,e)
retourner l’hypothèse Hmax, maxi, maxj.
Sortie: e1,…ei,…emaxi
Figure 21: L’algorithme de recherche DP.
Nous présentons l’algorithme qui implémente l’idée de [Nießen et al. 1998]. L’entrée de l’algorithme est le texte source à traduire et la sortie est le texte traduit dans la langue cible.
L’algorithme mémorise toutes les informations nécessaires dans une table que nous illustrons dans un exemple (section 5.1.5). Il est divisé en trois phases:
- Dans la première phase, il s’agit de la préparation de données pour initialiser la table de recherche et sélectionner le vocabulaire actif.
- La seconde partie est la principale qui remplit la table de recherche. Pour remplir la case (i,j), l’algorithme cherche dans toutes les cases de la ligne i-1 et dans les positions sources libres k.
- La troisième partie de l’algorithme implémente la méthode du chaînage en arrière (backtraking) qui sert à chercher la meilleure traduction. Enfin, construire le texte traduit.
5.1.5 Les problèmes rencontrés durant l’implémentation
Dans cette section, on parle des principaux problèmes rencontrés durant l’implémentation de cet algorithme:
- Estimer la longueur de la phrase cible parce que dans la plupart des cas la phrase source n’a pas la même longueur que sa traduction.
- Sélectionner les traductions possibles de chaque mot source.
Une phrase française de 10 mots peut aussi bien être traduite par une phrase anglaise de 8 que par une phrase de 13 mots.
Sur un corpus de 66 paires de phrases (français/anglais) telles que les phrases françaises sont de 10 mots, la longueur des phrases anglaises se varie entre 6 et 14 mots anglais, la moyenne est de 9.64 mots. (Voir la distribution, figure 22)


Figure 22: La distribution de longueur des traductions anglaises des phrases françaises de 10 mots.
À ce fait, on trouve plusieurs problèmes lors des calculs des probabilités P(I|J) et P(i|j,J,I) de l’équation (5.4) ainsi que la détermination d’une des dimensions de la table de recherche. Nous avons abordé ce problème dans la section (5.1.2).
Fixant une longueur maximale (Imax) pour la traduction, le modèle de longueur utilisé dans l’équation (5.8) peut accorder une probabilité P(I|J) à chaque paire de phrases de longueur I et J où I varie entre 1 et Imax.
Nous nous intéressons maintenant au problème de la sélection du vocabulaire actif qui peut être associé à chaque mot français. Nous utilisons pour cela le modèle de transfert P(ei|fj). Formellement nous cherchons :
![]()

Où P(fj|ei) est la probabilité de transfert donnée par le modèle de traduction IBM2 et P(ei) est la probabilité donnée à ei par un modèle unigramme.
Exemple :
Étant donnée cette phrase à traduire : nous avons vu
Selon notre modèle de transfert, On trouve que nous est associé à 6874 mots anglais, avons à 3608 mots et vu à 2176 mots.
On voit clairement à partir de cet exemple que chaque mot français est associé à un nombre important de mot anglais alors un filtrage est nécessaire pour réduire ce nombre de mots. D’habitude on sélectionne les meilleures N traductions.
En appliquant la formule (5.9), voici les 7 mots anglais les plus probablement associés à chaque mot français. Nous comparons ce score à celui obtenu en ne tenant pas compte du modèle unigramme.
En pratique nous observons qu’il est préférable d’utiliser l’équation (5.9). (les mots sont classés selon les scores de probabilités par ordre décroissant).
- P(fj|ei) nous : we us ourselves canting beckoning radiator the
- P(fj|ei)×P(ei) nous : we us our the this it that
- P(fj|ei) avons : our have need because saw we heard
- P(fj|ei)×P(ei) avons : we have our is was been heard
- P(fj|ei) vu : seen saw amputee cartoonist watched seely given
- P(fj|ei)×P(ei) vu : seen saw see given had been because………
5.1.6 Exemple
Dans cette section, on présente un exemple afin d’illustrer l’algorithme, son fonctionnement, la modalité de recherche, le meilleur score et enfin comment construire la traduction par le backtracking.
La phrase française à traduire est : Nous avons vu
Noter que dans nos expériences, les valeurs des probabilités sont remplacées par leur logarithme (à base deux) (Log[P]). Ceci nous permet, et de simplifier nos calculs et de gérer les problèmes de précisions dûes à la multiplication des termes entre 0 et 1.
On commence par faire le choix d’une longueur maximale de la traduction. la phrase française contient trois mots, nous décidons arbitrairement que la traduction n’en contiendra pas plus de 5. Un modèle de longueur est appliqué pour déterminer la longueur cible étant donnée la longueur source.
On décide ensuite d’un nombre maximum de mots associable à chaque mot français. Ceci n’est pas commandé par l’équation (5.4) mais permet en pratique de réduire les temps de calcul. Dans cet exemple, nous prenons comme valeur 10.
La table de recherche est donc dans notre exemple de dimensions 5 par 3. Chaque case (i,j) mémorise le dernier mot de l’hypothèse ei aligné au(x) mot(s) français ![]()

Un sous-ensemble des items construits lors de la recherche est illustré en figure 20. Chaque item est décrit par un 6-uplet (ei,c,f,s,j,ei-1) où ei est le mot anglais, c est le nombre de mots français couverts, f est la fertilité de ei, s est le score de l’hypothèse, j et ei-1 sont respectivement la position et le mot précédent, ce sont des informations de backtraking.
Par exemple : (saw, 3, 2, -31.6374, 0, we ) ; saw est le mot, 3 est la couverture, 2 est la fertilité, -31.6374 est le score de l’hypothèse, cette hypothèse est une extension d’une autre hypothèse se terminant par we.
L’information de l’hypothèse avant extension se trouve en ligne précédente (c’est toujours le cas) et colonne 0 (information de retour en arrière). L’espace de recherche est organisé sous la forme d’une table à 4 dimensions T.
L’hypothèse (saw, 3, 2, -31.6374, 0, we ) s’y trouve à la case T[1,1,saw,3]. Les cellules contenues dans T[1,1] contiennent toutes les hypothèses en cours dont le premier mot cible est aligné avec le premier mot source.
La table est remplie en étendant chaque hypothèse valide en position i-1 par un nouveau mot en position i. Un mot peut être aligné à 0,1 ou … l mots français dans ce cas le score associé à une hypothèse h est étendu par le score du mot précédent, le score donné par le trigramme P(ei|ei-1 ei-2) et le modèle de traduction IBM2 en n’alignant ei à aucun mot à 1 ou… l mots (fertilité modélisée).
Plus formelle: pour le mot ei de fertilité de l le score S de l’hypothèse est :
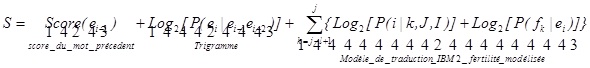

| (be, 1, 0, -118.821, 0, to)(tell, 1, 0, -124.36, 0, to)
(we, 2, 1, -75.7717, 2, 4) (forced, 2, 0, -101.34, 0, we) (tell, 2, 1, -85.749, 2, to) (have, 3, 1, -75.8361, 1, we) (situation, 3, 0, -104.003, 0, a) (tell, 3, 1, -85.9551, 1, we) |
(be, 1, 0, -140.719, 1, to)(tell, 1, 0, -146.258, 1, to)
(we 2, 1, -78.7303, 2, ,) (forced, 2, 0, -105.497, 1, we) (tell, 2, 0, -109.247, 1, we) (have, 3, 1, -63.4354, 2, we) (situation, 3, 0, -95.7367, 1, this) (tell, 3, 0, -92.1114, 1, we) |
(to, 1, 0, -85.4202, 2, going)(tell, 1, 0, -92.0437, 2, to)
(of, 2, 0, -68.5801, 2, 1411) (situation, 2, 0, -76.4878, 2, the) (forced, 2, 0, -79.8977, 2, of) (the 3, 0, -58.9385, 2, in) (situation, 3, 0, -64.3124, 2, the) |
| (to, 1, 0, -90.6244, 0, going)(forced, 1, 0, -98.8266, 0, have)
(we, 2, 1, -64.7879, 2, time) (tell, 2, 1, -74.6024, 2, to) (we, 3, 1, -64.8327, 1, time) (situation, 3, 0, -100.527, 0, our) (tell, 3, 1, -76.9989, 1, us) |
(to, 1, 0, -108.929, 1, going)(tell, 1, 0, -115.02, 1, to)
(have, 2, 1, -64.7508, 2, we) (tell, 2, 0, -86.8764, 1, to) (we, 3, 1, -49.9875, 2, that) (situation, 3, 0, -79.4187, 1, a) (tell, 3, 0, -81.5409, 1, seen) |
(, , 1, 0, -70.1086, 2, time)(forced, 1, 0, -77.7886, 2, have)
(the 2, 0, -53.5531, 2, in) (situation, 2, 0, -59.2954, 2, the) (the 3, 0, -44.0328, 2, seen) (in, 3, 0, -47.2669, 2, seen) |
| (have, 1, 0, -63.3408, 0, could)(forced, 1, 0, -71.1479, 0, are)
(us, 2, 1, -51.8878, 2, to) (forced, 2, 0, -60.5926, 0, are) (we, 3, 2, -55.6962, 2, what) (situation, 3, 0, -82.2798, 0, the) (forced, 3, 0, -75.8484, 0, we) |
(to, 1, 0, -78.3212, 1, have)(forced, 1, 0, -83.708, 1, have)
(have, 2, 1, -42.2313, 0, could) (forced, 2, 0, -55.564, 1, have) (seen, 3, 1, -38.2634, 2, have) (forced, 3, 0, -74.0786, 1, have) |
the 1, 0, -53.954, 2, to)(forced, 1, 0, -64.2729, 2, was)
(the 2, 0, -37.656, 2, saw) (situation, 2, 0, -51.7445, 2, see) (seen, 3, 1, -28.5164, 1, have) (forced, 3, 1, -44.5886, 1, have) |
| (have, 1, 0, -35.2632, 0, we)(forced, 1, 0, -44.4243, 0, we)
(we, 2, 1, -23.9373, 1, we) (situation, 2, 0, -54.0669, 0, we) (tell, 2, 1, -32.5504, 1, we) (we, 3, 2, -38.1071, 2, when) (situation, 3, 0, -83.3688, 0, we) (tell, 3, 1, -55.5457, 1, saw) |
(have, 1, 0, -46.3813, 1, we)(forced, 1, 0, -57.7353, 1, we)
(have, 2, 1, -18.2373, 0, we) (forced, 2, 0, -81.2807, 1, saw) (saw, 3, 2, -31.6374, 0, we) (saw, 3, 2, -31.6374, 0, we) (are, 3, 2, -56.904, 0, we) |
(the 1, 0, -39.3, 2, since)(saw, 2, 1, -23.5968, 0, we)
(situation, 2, 1, -38.1285, 0, we) (saw, 2, 1, -23.5968, 0, we) (saw, 3, 1, -31.9204, 0, we) (saw, 3, 1, -31.9204, 0, we) |
| (we, 1, 1, -11.458, 0, Début)(give, 1, 1, -26.3494, 0, Début)
(must, 1, 1, -30.0417, 0, Début) (we, 2, 2, -19.7816, 0, Début) (give, 2, 2, -54.4216, 0, Début) (must, 2, 2, -58.114, 0, Début) (we, 3, 3, -49.0835, 0, Début) (now, 3, 3, -64.9999, 0, Début) (give, 3, 3, -83.7236, 0, Début) |
(we, 1, 1, -19.1016, 0, Début)(found, 1, 1, -37.7142, 0, Début)
(have, 1, 1, -38.1074, 0, Début) (seen, 1, 1, -33.8516, 0, Début) (saw, 2, 2, -40.8197, 0, Début) (found, 2, 2, -51.2493, 0, Début) (have, 2, 2, -67.4093, 0, Début) (intend, 2, 2, -65.8712, 0, Début) (seen, 2, 2, -41.7503, 0, Début) |
(since, 1, 1, -29.419, 0, Début)(see, 1, 1, -40.2709, 0, Début)
(seen, 1, 1, -38.7929, 0, Début) (noticed, 1, 1, -41.1871, 0, Début) (saw, 1, 1, -41.4us, 0, Début) |
| Nous | Avons | Vu |
Figure 23: Le format de la matrice (mot, couverture, fertilité, score, position précédent, mot précédent), l’accès à une hypothèse se fait par (mot, couverture, ligne, colonne).
Une fois la table complètement remplie, on cherche l’hypothèse de score maximal qui couvre l’ensemble des positions sources (3 mots dans notre cas). Cette hypothèse est décrite par l’item (seen, 3, 1, -28.5164, 1, have). Pour obtenir la solution, il faut alors reculer (backtraking).
On cherche l’antécédent qui est (have, 2, 1, -18.2373, 0, we) puis la précédente (we, 3, 3, -49.0835, 0, Début) qui est le premier mot parce que cet item a un antécédent (0,Début), alors on s’arrête et la traduction est construite.
Si on ne prend pas en compte le meilleur score dans la matrice et on cherche les meilleures traductions de différentes longueurs telle qu’elles sont couvrantes tous les mots sources on obtient :
Longueur 1
Dans la ligne 1 de la matrice, on trouve cette hypothèse, (we, 3, 3, -49.0835, 0, Début), a le meilleur score et une couverture 3, c’est-à-dire elle couvre tous les mots sources, on la considère comme une solution et le backtracking s’arrête au mot Début.
Alors traduction est d’un seul mot : we
Longueur 2
Dans la ligne 2, (saw, 3, 2, -31.6374, 0, we) est la meilleure hypothèse. Elle vient de l’item identifié par (mot= we, couverture= 1, ligne= 0, colonne= 0) qui est au Début.
La traduction est de deux mots : we saw
Longueur 3
Dans la ligne 3, (seen, 3, 1, -28.5164, 1, have) est la meilleure hypothèse. Elle vient de l’item identifié par (have, 2, 1, 1), en reculant (backtracking), on arrive à celui-ci (have, 2, 1, -18.2373, 0, we), et à son tour, ce dernier vient de celui qui est identifié par (we, 1,0,0). On trouve cet item (we, 1, 1, -11.458, 0, Début) à la fin de backtracking.
Alors la traduction est de trois mots : we have seen
On note que la traduction se construit de la fin de la phrase jusqu’au début.
Longueur 4
De la même manière, (the 3, 0, -44.0328, 2, seen) -> (seen, 3, 1, -28.5164, 1, have)->
(have, 2, 1, -18.2373, 0, we)-> (we, 1, 1, -11.458, 0, Début)
La traduction est de quatre mots : we have seen the
Longueur 5
(the 3, 0, -58.9385, 2, in) ->(in, 3, 0, -47.2669, 2, seen)-> (seen, 3, 1, -28.5164, 1, have)->
(have, 2, 1, -18.2373, 0, we)-> (we, 1, 1, -11.458, 0, Début)
La traduction est de cinq mots : we have seen in the
Exemple de traduction et comparaison après et avant le filtrage:
1- Chaque mot français a 50 traductions en anglais (N=50) et un seuil BETA=106
| Phrase source | Traduction | Temps(sec.) | VCB actifs | |
| 1 | nous | We | ~0 | 50 |
| 2 | nous avons | we have | 1 | 84 |
| 3 | nous avons vu | we have seen | 2 | 116 |
| 4 | nous avons vu des | we have seen some | 7 | 150 |
| 5 | nous avons vu des solutions | we have seen some solutions | 23 | 195 |
| 6 | nous avons vu des bonnes solutions | we have seen some positives solutions | 66 | 239 |
| 7 | nous avons vu des bonnes solutions. | we have seen some positive alternatives. | 191 | 263 |
| 8 | nous avons vu des bonnes solutions avec vous | we have seen some positive solutions with you | 312 | 288 |
| 9 | nous avons vu des bonnes solutions avec vous . | we have seen some positive alternatives with you. | 619 | 335 |
Tableau 11: Les résultats de décodeur sans filtrage strict (N=50; BETA=106)
2- Chaque mot français a 15 traductions en anglais (N=15) et un seuil BETA=1.9
| Phrase source | Traduction | Temps(Sec.) | VCB actifs | |
| 1 | nous | We | ~0 | 15 |
| 2 | nous avons | we have | ~0 | 24 |
| 3 | nous avons vu | we have seen | ~0 | 33 |
| 4 | nous avons vu des | we have seen some | ~0 | 43 |
| 5 | nous avons vu des solutions | we have seen some solutions | 1 | 58 |
| 6 | nous avons vu des bonnes solutions | we have seen some ideas | 4 | 73 |
| 7 | nous avons vu des bonnes solutions. | we have seen some positive alternatives. | 9 | 88 |
| 8 | nous avons vu des bonnes solutions avec vous | we have seen some positive solutions with you | 15 | 93 |
| 9 | nous avons vu des bonnes solutions avec vous. | we have seen some positive alternatives with you. | 25 | 106 |
Tableau 12: Les résultats de décodeur avec un filtrage sur les nombres de mots anglais associés à chaque mot français (N=15) et un seuil (BETA=1.9) sur les hypothèses.
3- Chaque mot français a 7 traductions en anglais (N=7) et un seuil BETA=1.25
| Phrase source | Traduction | Temps(Sec.) | VCB actifs | |
| 1 | nous | We | 0 | 7 |
| 2 | nous avons | we have | 0 | 12 |
| 3 | nous avons vu | we have seen | 0 | 18 |
| 4 | nous avons vu des | we have seen | 0 | 24 |
| 5 | nous avons vu des solutions | we have seen some solutions | 1 | 31 |
| 6 | nous avons vu des bonnes solutions | we have seen some kind | 1 | 38 |
| 7 | nous avons vu des bonnes solutions. | we have seen some good answers. | 2 | 45 |
| 8 | nous avons vu des bonnes solutions avec vous | we have seen some good answers with you | 5 | 49 |
| 9 | nous avons vu des bonnes solutions avec vous. | we have seen some good answers with you. | 8 | 55 |
Tableau 13: Les résultats de décodeur avec un filtrage sur les nombres de mots anglais associés à chaque mot français (N=7) et un seuil (BETA=1.25) sur les hypothèses.
Regardons les tableaux et comparons les résultats. Au niveau du temps et de nombres de vocabulaires; les temps ont été diminués d’une façon remarquable.
- Pour la phrase de 9 mots, le temps de traduction est réduit de 619 secondes à 25 secondes pour la même réponse et à 8 secondes pour une autre réponse qui est aussi considérée comme une traduction acceptable.
- Pour 5 mots français, le temps est réduit de 23 secondes à une seconde pour les mêmes réponses.
- La phrase de 4 mots (nous avons vu des), dans les deux premiers tableaux, a été traduite par (we have seen some), cependant elle est traduite par (we have seen ) avec les contraintes strictes dans le troisième tableau, c’est un exemple de perte de certaines hypothèses importantes.
En examinant la matrice de toutes les hypothèses, on trouve que ce résultat est favorisé parce qu’il a un score de -37.7094, par contre (we have seen some) a un score -37.8372.
5.1.7 Exemples de résultats obtenus
Les phrases sont prises de HANSARD, corpus test, c’est-à-dire l’entraînement n’a pas été fait sur ces phrases. On peut avoir une traduction parfaite (phrase 1) et d’autres acceptables (phrases 2, 3 et 4 ) et un peu loin (dernière phrase).
| Phrase | mots | Les phrases sources et les traductions |
| Source | 5 | le jeudi 17 avril 1986 |
| Décodeur | 6 | thursday , april 17 , 1986 |
| Humain | 6 | thursday , april 17 , 1986 |
| Source | 7 | la charte canadienne des droits et libertés |
| Décodeur | 7 | the Canadian charter of rights and freedoms |
| Humain | 6 | Canadian charter of rights and freedoms |
| Source | 12 | m. nunziata : monsieur le président , j’ invoque le règlement . |
| Décodeur | 12 | mr. nunziata : mr. speaker , i rise on a settlement . |
| Humain | 12 | mr. nunziata : mr. speaker , on a point of order . |
| Source | 17 | les pétitionnaires demandent que la loi canadienne sur la santé soit inscrite dans la constitution canadienne . |
| Décodeur | 16 | the petitioners ask that the canadian act of health be put into the canadian constitution . |
| Humain | 16 | these petitioners ask that the canada health act be enshrined in the constitution of canada . |
| Source | 20 | ils doivent engager des frais importants pour assister et participer aux audiences de l’ office national de l’ énergie . |
| Décodeur | 16 | they should hire some substantial costs to participate and assist people in the national energy . |
| Humain | 17 | they are faced with substantial costs to attend and to participate in national energy board hearings . |
| Source | 19 | je n’ ai pas l’ intention de faire une longue déclaration , mais je voudrais faire valoir quelques points . |
| Décodeur | 17 | I do not have the intention to make a long statement and i would points . |
| Humain | 19 | i do not want to make a long statement but i would like to make a few points . |
| Source | 17 | la douleur doit être encore plus vive lorsque l’ enfant a été victime d’un meurtre. |
| Décodeur | 16 | the pain be even more intense when the child has been a victim of murder . |
| Humain | 19 | the pain these parents feel is even greater knowing they have lost a child as a murder victim . |
| Source | 19 | étant moi-même mère , je peux imaginer à quel point cela doit être dur de perdre un enfant . |
| Décodeur | 15 | I , as my homeland cannot conceive how be in a baby out tough . |
| Humain | 16 | as a parent I can imagine how difficult it would be to lose a child . |
Tableau 14: des exemples de corpus test de Hansard et une comparaison avec la traduction humaine. Un filtrage a été appliqué N=10, BETA=1.5.

