Le Serverless, les prérequis et les contre-indications
1.4 Les prérequis pour introduire le serverless dans notre organisation
1.4.1 Un découpage en fonctions
Il est conseillé de repenser l’application – au moins partiellement – pour la découper en fonctions qui détiennent chacune une responsabilité précise.
Ce découpage est comparable au passage d’une architecture monolithique à une architecture en microservices.
Par conséquent, si notre produit est déjà basé sur une architecture microservices, passer au moins partiellement au serverless sera bien plus facile.
1.4.2 La compatibilité du code
Étant donné que la fonction sera hébergée et déployée sur un Cloud Provider serverless, elle doit respecter les règles mises en place par le Cloud Provider choisi.
Les deux règles principales sont :
– les langages : AWS Lambda n’accepte par exemple nativement que des fonctions écrites en C#, Java, Node.js, Go, Ruby ou Python. Des solutions existent néanmoins afin de pouvoir faire fonctionner n’importe quel autre langage, comme PHP par exemple, sur Lambda.
Pour notre cas nous avons fait tourner nos fonctions sur Lambda en utilisant le langage PHP déployer à l’aide d’un plugin du WordPress
– le respect du temps limite d’exécution de la fonction (15 minutes sur AWS Lambda mais ce temps limite est abaissé à 30 secondes si l’événement qui invoke la fonction est une requête HTTP)
Screenshot de la console AWS
13 www.serverless.com, consulté le 14 Avril 2020 à 16h18
1.5 Contre-indications de serverless
Le serverless est plein de promesses mais il n’est pas adapté pour tous les cas d’usages.
Du fait de la limitation du temps d’exécution, il est inadapté aux tâches lourdes et complexes comme du traitement vidéo, ou aux tâches qui nécessitent de maintenir une connexion active avec ses clients.
D’autre part, si notre code est exécuté à intensité constante, le serverless coûtera plus cher à notre organisation qu’un hébergement classique14.
Néanmoins, ces contraintes s’appliquent peut-être uniquement à une partie de notre application.
Dans le cas où d’autres parties, comme l’authentification par exemple, ne nécessitent pas de ressources allouées en permanence, il est possible de les externaliser dans une fonction serverless.
1.6 Quelques exemples de cas recourant au serverless15
Afin d’illustrer le fonctionnement et l’approche Serverless, voici des exemples de Use Cases.
1. Application Web
Prenons l’exemple d’un site e-commerce. Il s’agit d’une application Web 3- tiers avec la logique côté serveur.

Figure 6: exemple d’un site e-commerce
Avec cette architecture, le client ne contient pratiquement aucune logique comparée au serveur (authentification, navigation de page, recherche, transactions).
Avec une architecture Serverless, cela pourrait finir par ressembler davantage à ceci :
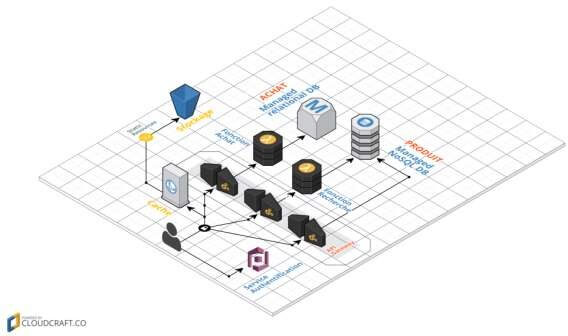
Figure 7: Architecture Serverless
Il s’agit d’un exemple de transposition de l’architecture précédente en Serverless. Il y a un certain nombre de changements importants qui se sont produits ici.
14 www.serverless.com, consulté le 14 Avril 2020 à 17h00
15 www.serverless.com, consulté le 14 Avril 2020 à 17h22
Notons que ce n’est pas une recommandation d’une migration architecturale, on utilise simplement comme un outil pour exposer certains concepts sans serveur.
– Plus besoin d’héberger nos fichiers Web sur un serveur, un simple
bucket et un outil de gestion du cache peuvent suffir.
– Nous avons supprimé la logique d’authentification et l’avons remplacée par un service tiers BaaS (Auth0, AWS Cognito, …).
– En utilisant un autre exemple de BaaS, nous avons permis à un client d’accéder directement aux données (listes de produits), hébergées par un tiers (AWS Dynamo, Firebase).
Nous pouvons aussi établi des règles de sécurité strictes liées aux profils utilisateurs et ainsi gérer les restrictions d’accès aux données.
– Les deux points précédents impliquent un changement important des rôles des tiers : la logique est passée du serveur au client (exemple : suivi d’une session utilisateur, UX, lecture de données et affichage dans une vue utilisable.
– Certaines fonctionnalités sont à garder côté serveur, par exemple, si elles impliquent des calculs intensifs ou nécessitent l’accès à des quantités importantes de données (recherche de produits).
Pour cette fonctionnalité, au lieu d’avoir un serveur toujours en cours d’exécution, nous pouvons implémenter une fonction FaaS qui répond aux requêtes HTTP via une API Gateway.
– Finalement, nous pouvons remplacer la fonctionnalité “Achat” par une autre fonction FaaS, en choisissant de la garder sur le côté serveur pour des raisons de sécurité.
Avec ce changement d’architectures, nous avons un nouveau panel d’outils à notre disposition comme l’API Gateway.
Pour faire simple, cet outil permet de définir des endpoints sécurisés accessible de l’extérieur et de rediriger l’appel vers un service de traitement (génération d’un événement, lancement d’une fonction) qui une fois fini pourra retourner des données selon les besoins.
2. Application basée sur les événements (Event-driven)
Un autre Use Case d’architecture Serverless est l’analyse et le traitement de données asynchrones.
Prenons un cas que nous connaissons tous, le tracking d’activités des utilisateurs d’une application. Le besoin est d’arriver à connaître les activités précises d’un utilisateur sans impacter les performances de l’application.
Nous pourrons ainsi déporter la logique permettant l’envoi/réception d’un événement de navigation et son enregistrement au sein d’une base de données de type BaaS.
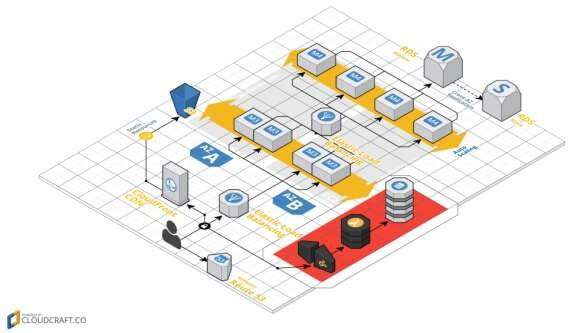
Figure 8: Architecture Serverless basée sur les événements
Voici l’exemple d’une architecture d’application Web basique possédant une fonction de tracking Serverless (zone rouge)
Ce service est assuré à l’aide d’une API Gateway, fonction permettant la déclaration d’endpoint et son mapping vers un service de traitement, ici une fonction de type FaaS.
Elle-même est en charge de l’enregistrement des données auprès d’une base de données de type BaaS.
3. L’IoT et son envoi d’informations effectué par des milliers de capteurs
Un autre exemple très en vogue de nos jours concerne l’IoT et son envoi d’informations effectué par des milliers de capteurs.
Nous n’avons aucun besoin d’une communication synchrone entre la partie serveur et les capteurs, en revanche l’objectif est la récupération des informations, son stockage et son analyse.
Un exemple de cet Use Case est la maintenance prédictive.
Après la récupération des données brutes issues des capteurs, des algorithmes vont les analyser et pouvoir conjecturer et “prédire” une panne ou un besoin de maintenance d’un équipement.
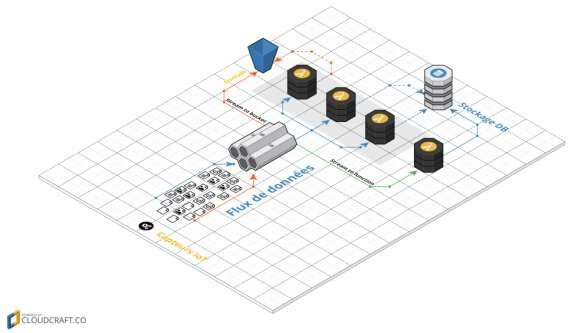
Figure 9: Architecture Serverless de L’IoT
Dans cette architecture nous utilisons des systèmes BaaS pour la gestion des flux de données (exemple : AWS Kinesis ou Google Cloud Pub/Sub) puis des systèmes FaaS pour le prétraitement, le pré-calcul ainsi que l’enregistrement de celles-ci dans une base de données fournis par un système BaaS.